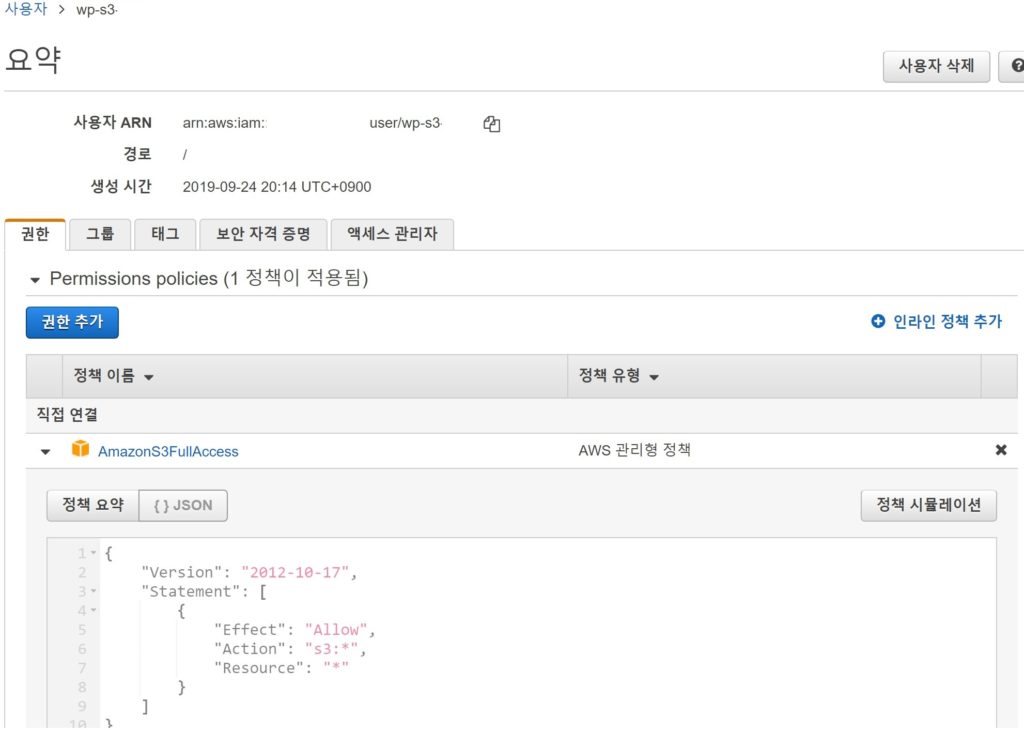
그리고 AmazonS3FullAccess 권한을 가진 사용자를 Programmatic access 방식으로 생성한다.
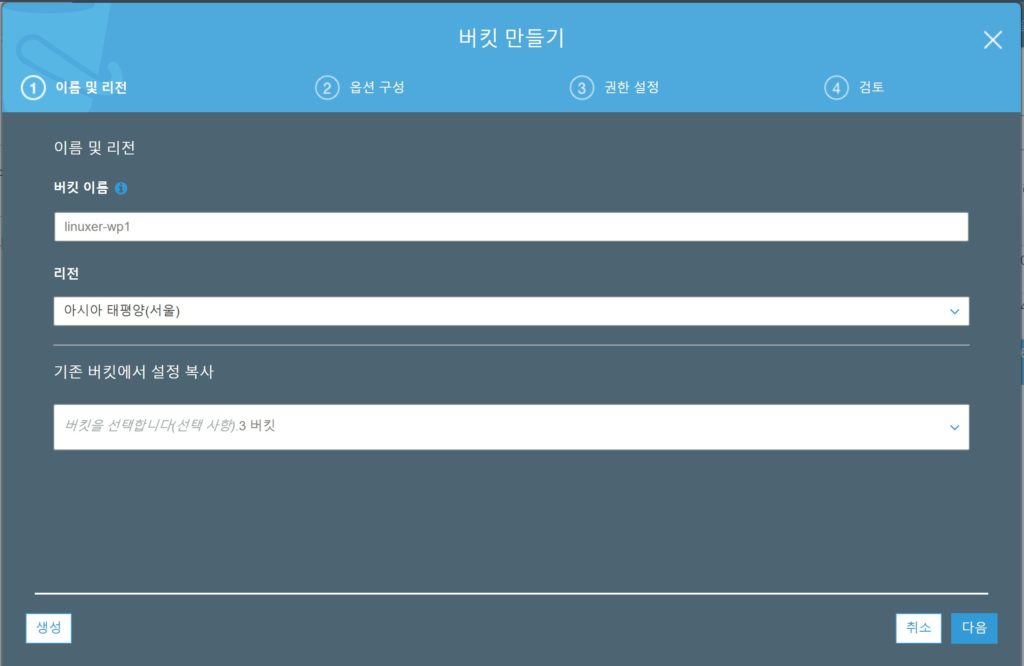
그리고 버킷을 생성한다. AmazonS3FullAccess full acces 권한을 줬는데 이 권한은 업로드 권한만 줘도 무방하다. 하지만 편한 테스트를위해 전체 권한을 부여하였다.
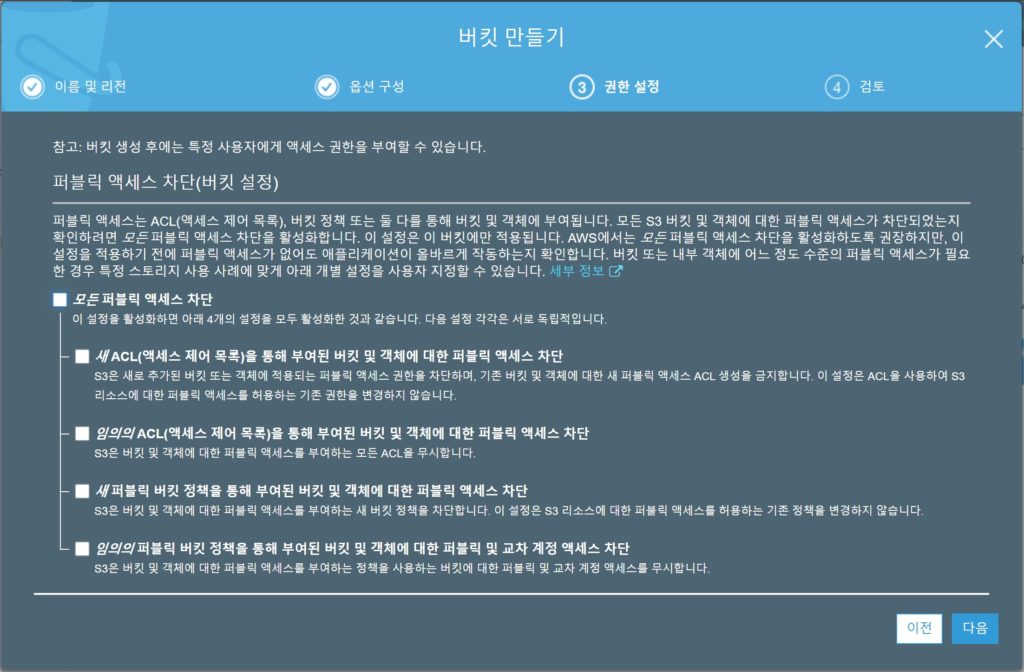
일단 모든 퍼블릭 엑세스 차단을 해제한다. 나머지는 모두 기본설정이다. 위 설정은 편한 설정을 위한 선택이므로 각자 개인의 선택을 요한다.
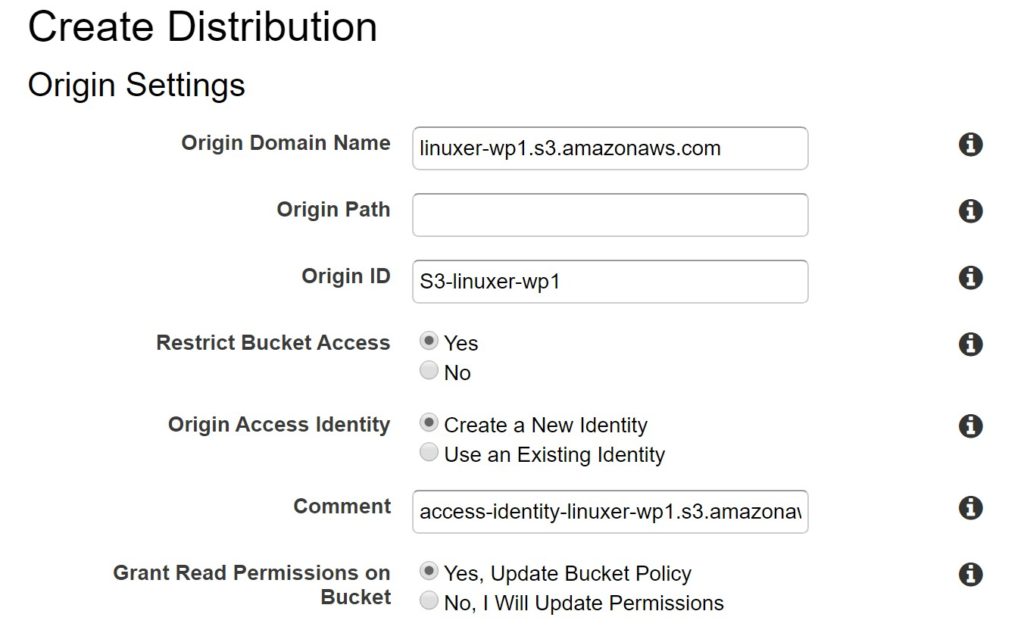
미리 wp-content/uploads 폴더까지 생성한다. 그리고 cloudfront 를 생성한다.
Restrict Bucket Access -yes Origin Access Identity - Create a New Identity Grant Read Permissions on Bucket - Yes, Update Bucket Policy 위 순서대로 선택하면 s3 버킷 정책이 자동으로 삽입된다.
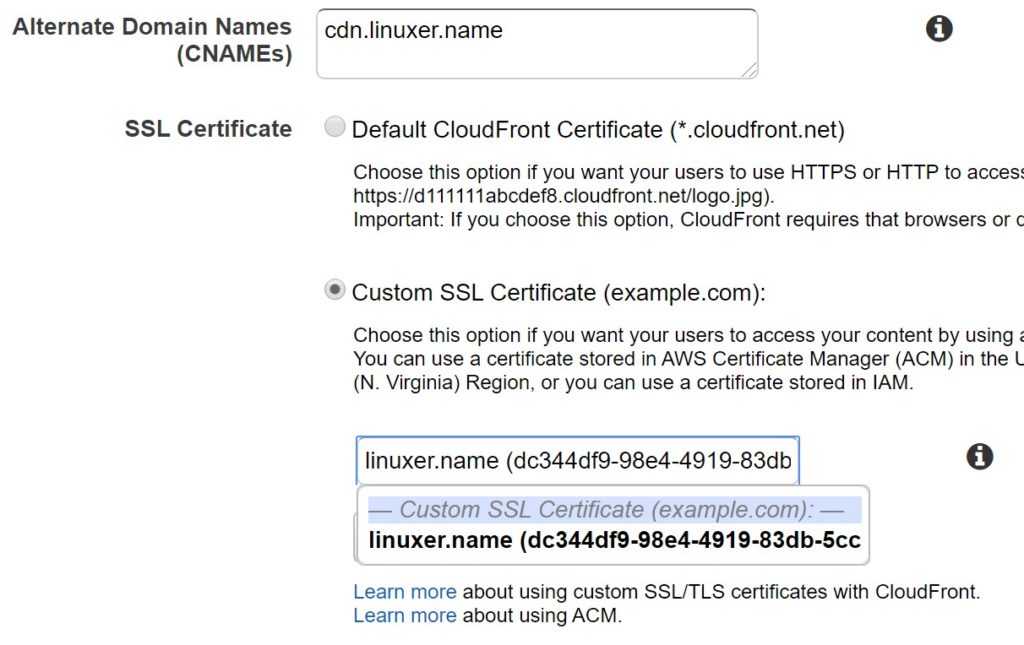
그리고 cloudfront는 https 로만 통신하기 떄문에 route53에 도메인을 생성하여 붙여주는게 좋다. 도메인을 붙일떈 acm 을 생성하여야 한다. acm은 버지니아 북부에서 생성한 acm만 사용할수 있다.
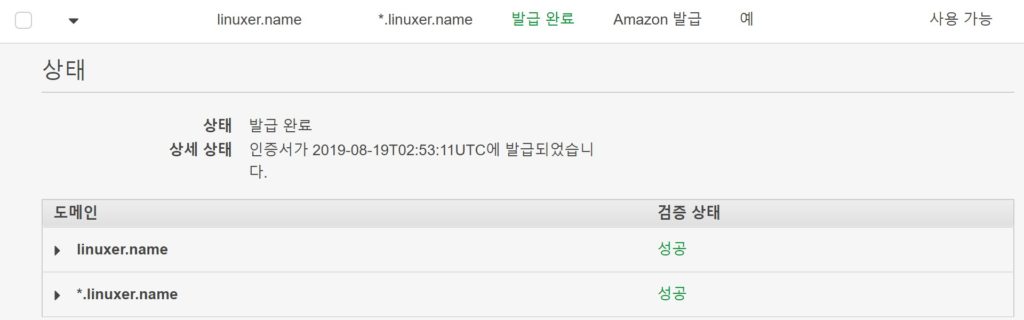
acm은 route53을 사용하면 버튼 클릭 한번으로 생성 가능하다. 하나의 acm에는 50개의 도메인을 추가할수 있다. 간단하게 linuxer.name *.linuxer.name 을 추가하였다. 여기에 linuxer.com 이나 linuxer.kr namelinuxer.net 등 여러가지의 도메인을 한꺼번에 추가하여 사용할수 있다.
이후 cloudfront 를 생성한다. 이후에 wordpress 플러그인 설정화면으로 진입한다.
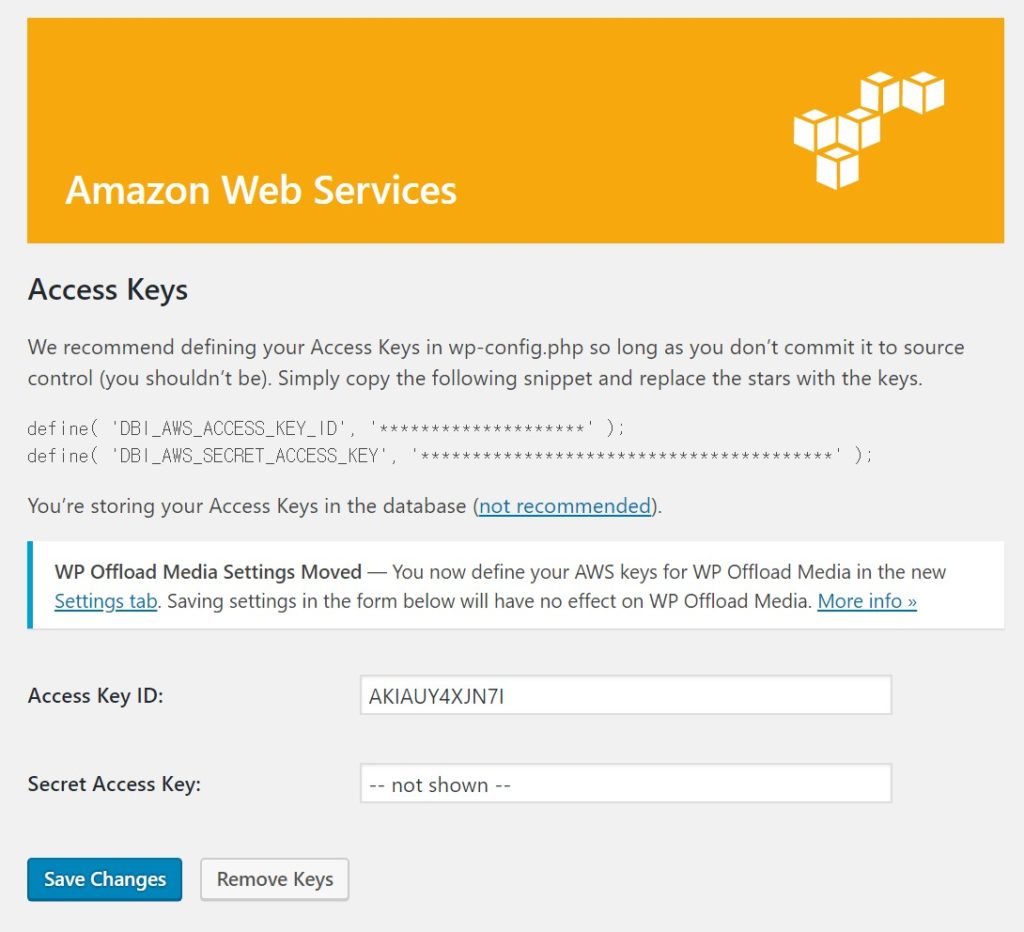
엑세스키와 시크릿키를 입력하고 save를 하면 디비에 저장이 된다. 디비에 저장하고 싶지 않을경우에 wp-config.php 파일에 추가를 한다.
그리고 플러그인 Offload Media Lite 으로 진입하여 cname 설정을 진행한다.
OFF 되어있는 버튼을 누르고 설정된 cloudfront 에 설정한 cname 을 입력한다. 이 설정을 마칠쯤이면 cloudfront 가 Deployed 상태로 변경될것이다.
그러면 이제 테스트 게시물을 작성하여 보자.
업로드가 정상적으로 이루어 지게 되면 이미지가 정상적으로 보이게되고 주소복사를 눌렀을떄 해당 페이지가 cdn 페이지로 열리면 정상적으로 upload-s3-cdn 이 구조로 생성이 된것이다.
그리고 s3 로 uploads 디렉토리를 이동하는것은 선택이다.
하지만 그부분도 진행하였다.
#aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]:ap-northeast-2
aws configure 명령어를 이용하여 이전에 만든 엑세스 키를 입력하고 리전을 지정한다. 그리고 aws s3 명령어를 이용하여 sync 한다.
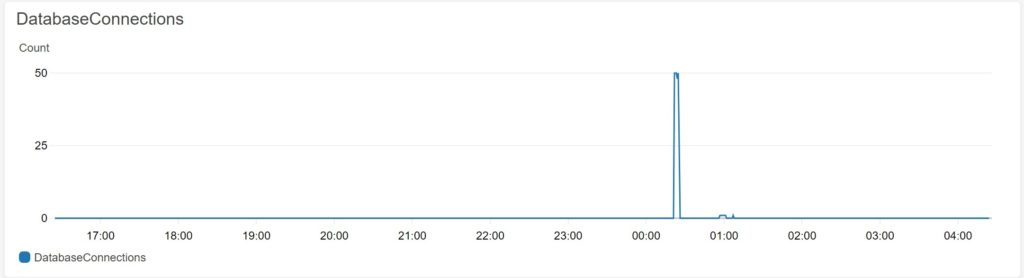
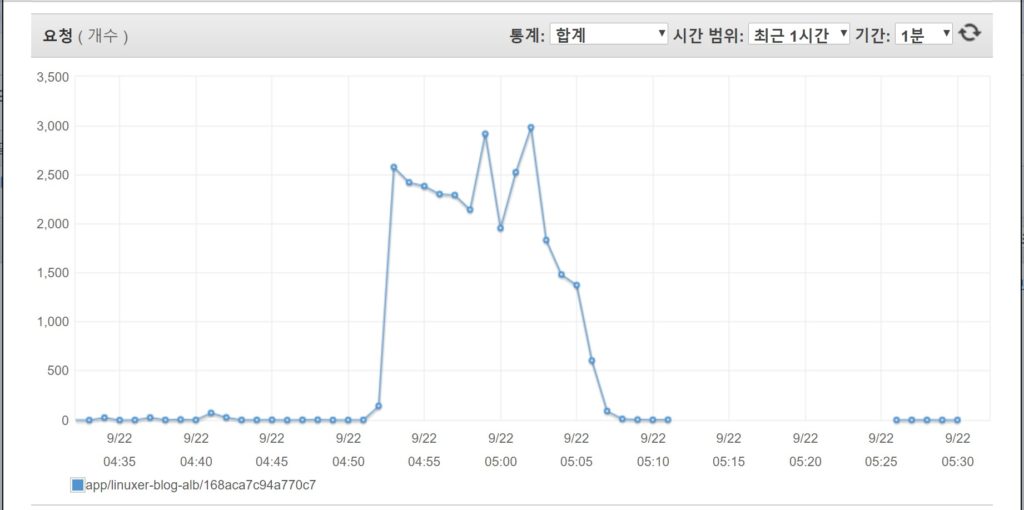
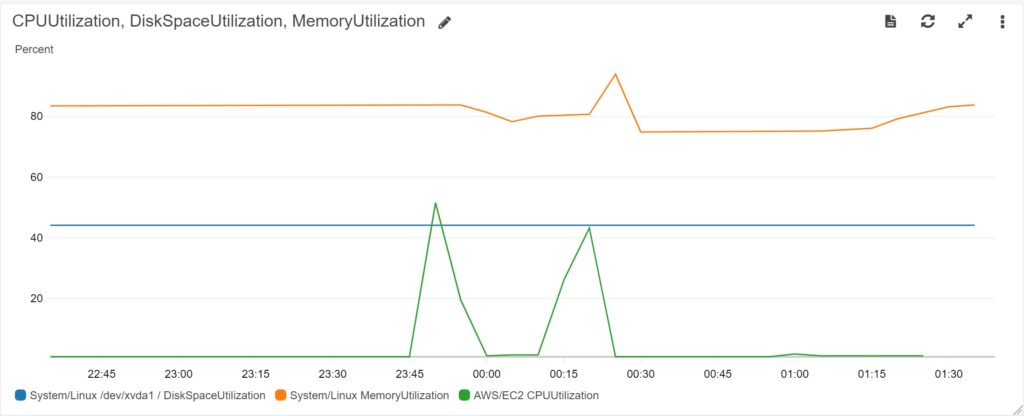
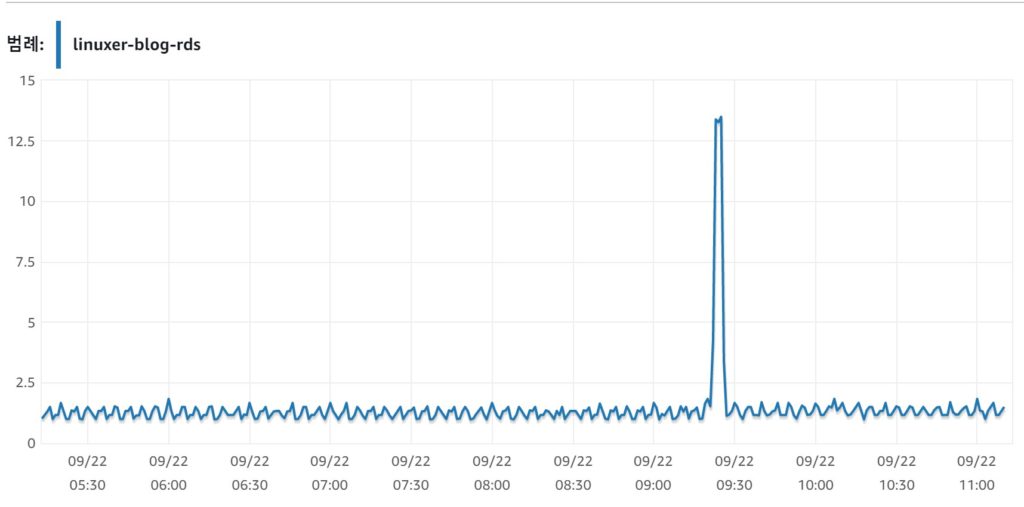
이만하면 충분히 web 인스턴스를 죽일수 있을거라 생각된다. 동접자만 확인하면 되는데 쓸데없이 흥분해서 30000번의 테스트를 보냈다.
로드벨런서 요청 갯수다. 그리고 인스턴스 안에서 로그로 리퀘스트 횟수를 확인해보니 약 9000개 정도..
어? 나쁘지 않은데? 싶다. 솔직히 내블로그가 동시접속자 1000명으로 몇번이나 견딜까 싶기도 하고... 하지만 여기서 그칠순 없다. 동접자를 더 늘려보자!
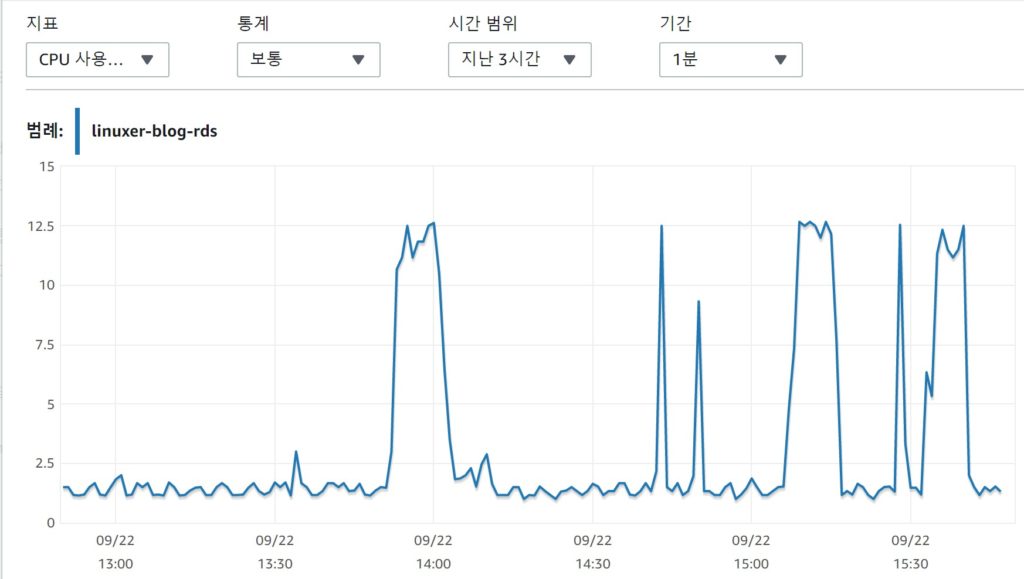
fpm 설정이 무리한 설정이 아니었을까? 사실 20개만 해도 cpu는 100%가까이 근접해 버리는터라 일단 메모리 리미트에 맞춰서 pm.max_spare_servers 설정을 수정하는것이 관건이라 본다. 간당간당하게 버티면서도 인스턴스는 죽지않는. 이과정은 사이트의 다운과 리스타트가 동반되는 아주 귀찮은 과정이다.
그래도 일단 근성을 보여서 테스트를 진행했다.
jmater를 이용하여 부하를 주고 인스턴스가 죽지 않을 만큼 php-fpm 에서 적당히 설정을 조절했다. 이경우 최대 부하시점에서 메모리가 아슬아슬하게 남아있을 경우를 찾아서 최적의 값을 찾아보았고 php-fpm.d/www.conf 를 수정하였다.
top 명령어 로 RES 부분을 보면 하나의 프로세스가 사용하는 메모리 양을 알수있다. 스크린샷에는 52M 정도이므로 프리티어는 1G의 메모리 까지 사용 가능하다. OS 까지 생각하면 대략 750M 정도 사용가능하다 생각하면 되는데 이기준으로 pm.max_spare_servers 를 15로 정했다.
다시 부하를 주었다.
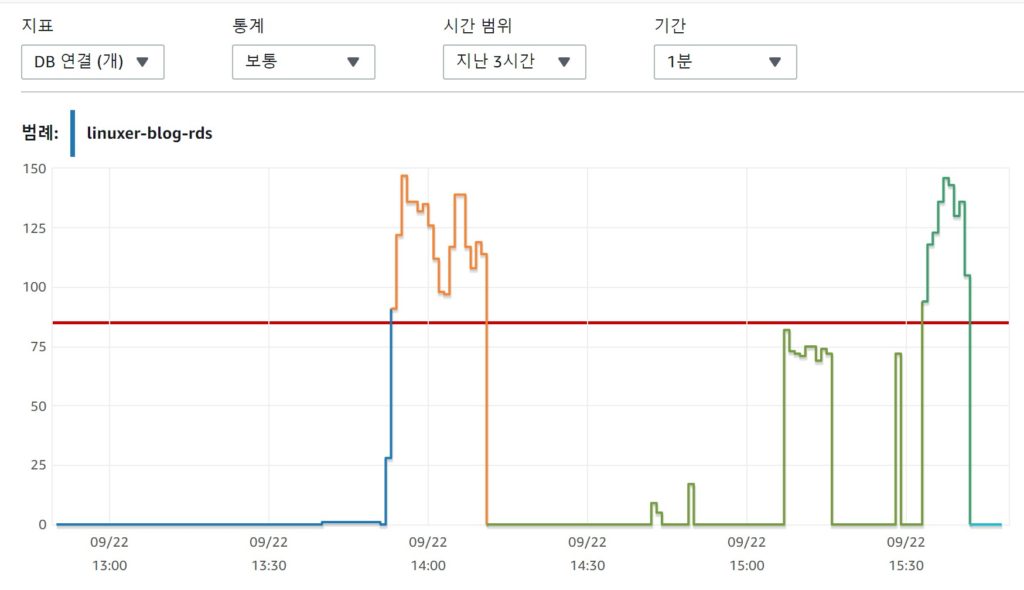
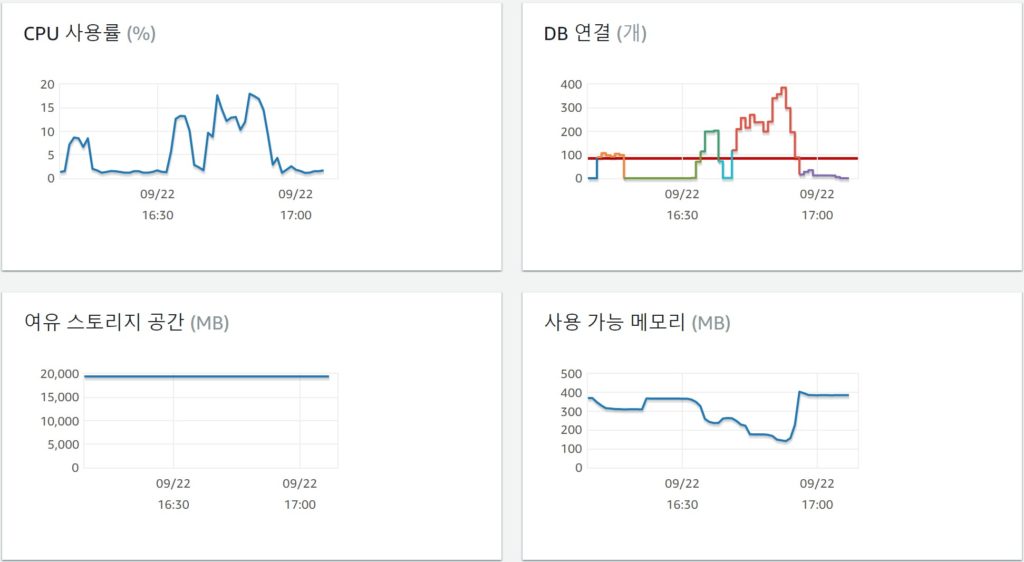
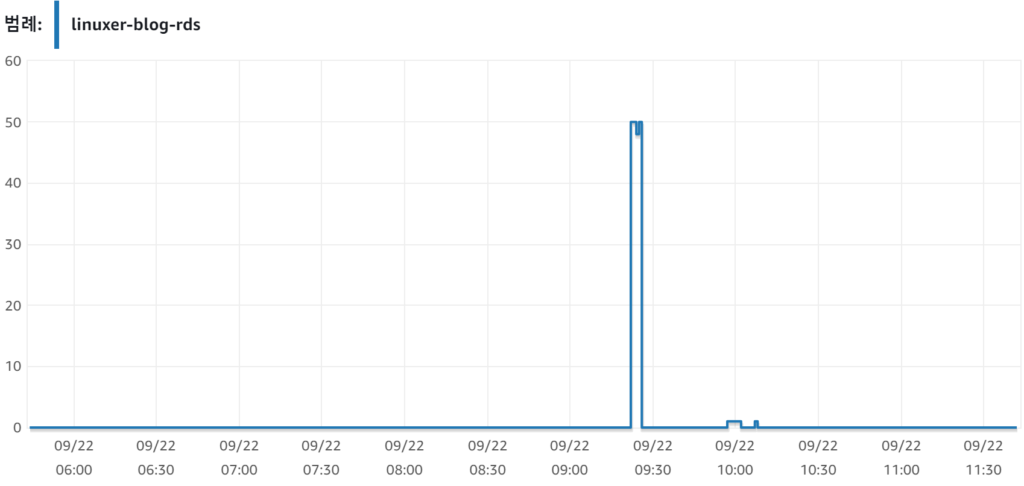
예상 처럼 남은 메모리가 50M 정도밖에 남지않고 잘돌아간다. 물론 이상황에 CPU는 100%다. 이실험을 시작한 이유는 rds에 최대 부하를 주는것이 목적이므로 pm.max_children 를 150 까지 늘렸다. 그리고 테스트를 하였다.
ec2 도 죽지않고 rds도 죽지 않았다. 아니 rds 는 max 커넥션에 걸리는데 cpu나 메모리는 13%....아마 내블로그에서 끌어낼수 있는 한계가 13%인거겠지...또르륵 그렇다면 이쯤작성하다 오기가 발동했다. 부하테스트를 시작한김에 rds 가 죽을때까지 인스턴스를 늘리기로 했다.
Auto Scaling 걸고 트리거 cpu는 60%로 사실 의미없다. 동시 접속 20개만 걸려도 cpu 100%인거.. 그렇지만 rds 를 죽이기로 했으므로 부하를 걸었다.
Auto Scaling 은 차근차든 인스턴스가 생성됬고 총5개까지 생성되었다. 사실 동접자 초당 120명 이면 인스턴스 모두 CPU가 100%다.... 무조건 부하를 주는건 잘못된 테스트 같아서 방법을 수정하였다. 1초당120번 접속 무한반복으로.
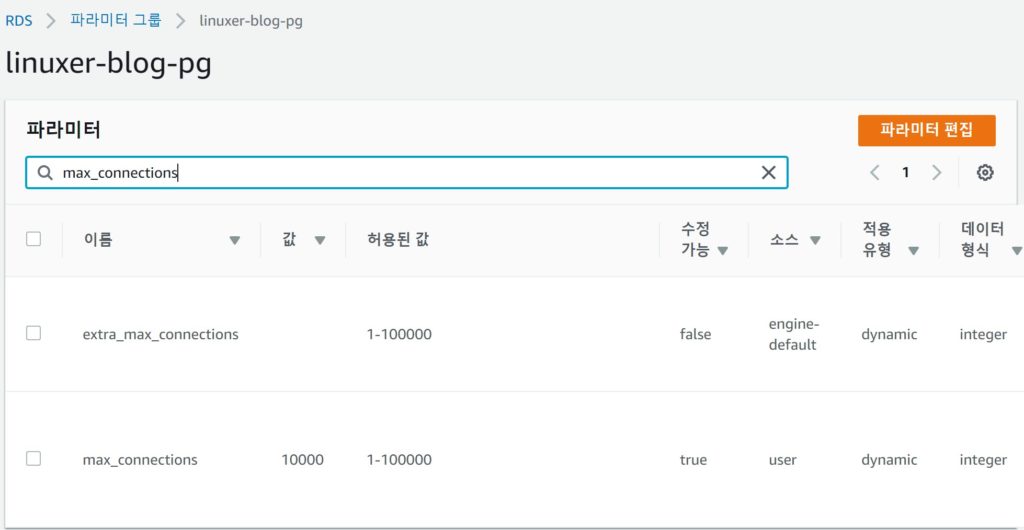
죽이기로 했으니 원래 t2.micro 사이즈의 max_connections 은 {DBInstanceClassMemory/12582880} 134다 이걸 10000으로 수정하였다.
rds의 파라미터그룹은 디폴트 파라미터그룹을 수정할수 없다. 따로 생성하여 수정해야 한다.
사실 aws에 galera를 셋팅하는것은…RDS때문에 아이러니한 선택일수 있으나,
온프레미스에서 쉽사리 셋팅하기 어려운 구성인 galera를 테스트 해보기로 하였다.
사실 이글을 쓰는 지금은 이미..블로그가 galera 위에서 돌고있다.
준비물을 챙겨보자.
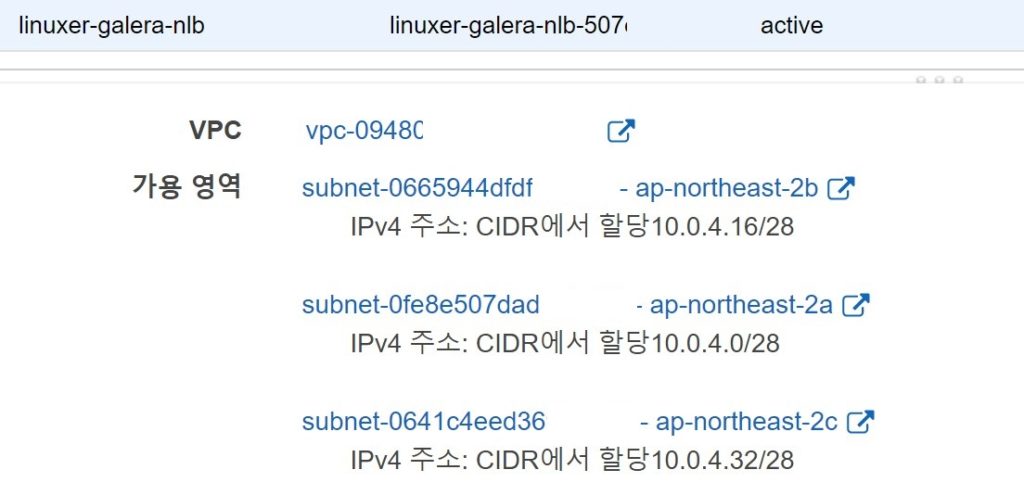
galera의 구성에는 multi-AZ를 위한 여러개의 서브넷이 필요하다.
한국리전의 A/B/C zone 을 모두 사용한다.
그리고 인스턴스를 생성한다.
인스턴스는 t3.nano를 활용하였다. 사용자가 많지 않아서 nano로 버틸수 있을거라 생각했다.
이과정에서 인스턴스만 5번이상을 만들었다 지웠다를 반복했는데 그이유는 B영역 때문이었다. 처음엔 t2.nano를 사용하려했으나 B영역에서 not support 발생으로 평소 사용해보고 싶었던 t3a 계열을 사용해 보려고 했으나, 마찬가지로 not support상태.. 결국 돌아서 t3.nano를 사용하게 되었다.
사용한 ami는 amazon linux 2 다.
인스턴스 생성후 보안 그룹은 따로 galera-sg를 생성하여 galera 인스턴스 끼리는 통신이 되도록 설정하고 웹서버 내부 IP로 3306만 열어 주었다.
인스턴스 셋팅할때는 EIP를 붙이고 작업하였다.
galera 셋팅은 아래와 같다.
#vi /etc/yum.repos.d/mariadb.repo
아래내용 삽입 설치할 mariadb 는 10.4 버전이다.
#MariaDB 10.4 CentOS repository list - created 2019-09-10 11:12 UTC #http://downloads.mariadb.org/mariadb/repositories/ [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.4/centos7-amd64 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1
여기서 수정할 내용은 wsrep_node_name='galera1' wsrep_node_address="10.0.4.27" wsrep_cluster_address="gcomm://10.0.4.9,10.0.4.27,10.0.4.43" 이 세부분이다. node name 은 노드를 분류할 이름으로 나는 galera1/2/3으로 넣었다. address 는 IP 인스턴스 각각 내부 IP를 넣어주고 클러스터 address는 클러스터 node address 를 나열한다.
여기까지 완료됬다면 galera 기본설정은 완료이다.
새로 만드는 클러스터일경우
#galera_new_cluster
명령어를 쳐주자. 이미 사용중이던 db를 클러스터로 만든다면 각각 mysql data를 클론뜨거나 dump 하여 데이터의 무결성을 검증할수 있도록 만들어준다음 클러스터로 엮어야한다.
이후 NLB를 추가하여
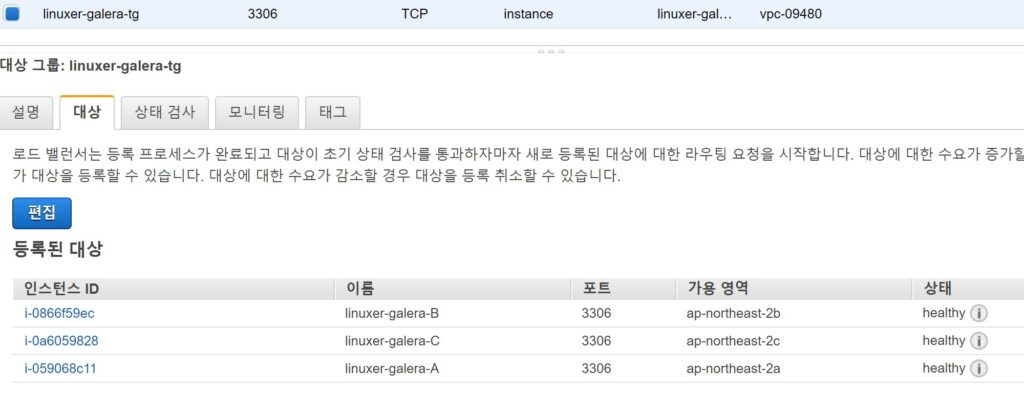
사용한 A/B/C 영역을 넣어주었고, 대상그룹에 galera cluster 를 넣어주었다.
상태가 healthy로 정상적으로 상태검사를 통과하는것을 확인할수 있었다.
이부분에서 확인할수 있었는데 상태검사를 통과하기 위해선 galera 보안그룹에 NLB가 위치한 subnet의 포트에 대해서 인바운드를 허용해 주어야지만 상태검사가 정상적으로 이루어 지는것을 확인하였다.
나는 이후에 NLB end point 로 rds 에서 db를 dump 하여 부어넣었다.
#mysqldump -h linuxer-blog-rds.com -u user -p DB > /home/linuxer-blog-db.sql
덤프후에 galrera cluster 로 접근하여 grant 권한을 웹서버에 맞춰서 설정해 주었다.
mysql>GRANT ALL PRIVILEGES ON db.* TO user@webserver_internal_ip IDENTIFIED BY 'password';
이후에 웹서버에서 밀어 넣었다.
mysql -h linuxer-galera-nlb.com -u user -p < /home/linuxer-blog-db.sql Enter password:
정상적으로 데이터를 복구하였고 이후에 디비커넥션을 수정하여 rds 에서 galera로 접속되도록 설정하였다.
rds t2.micro
mariadb galera
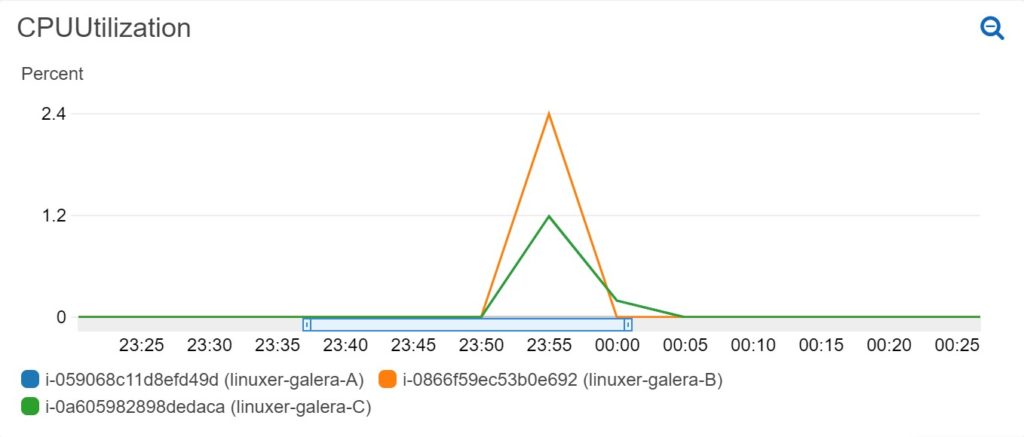
평균 0.20s 정도 불러오는 속도 차이가 난다.
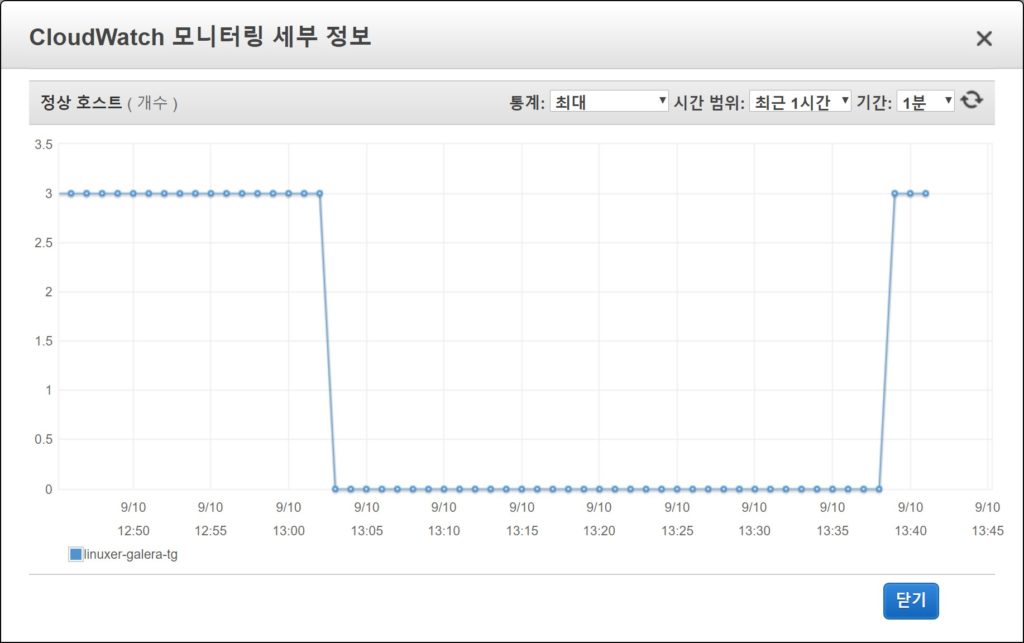
일주일간 galera cluster를 유지할 생각이다.
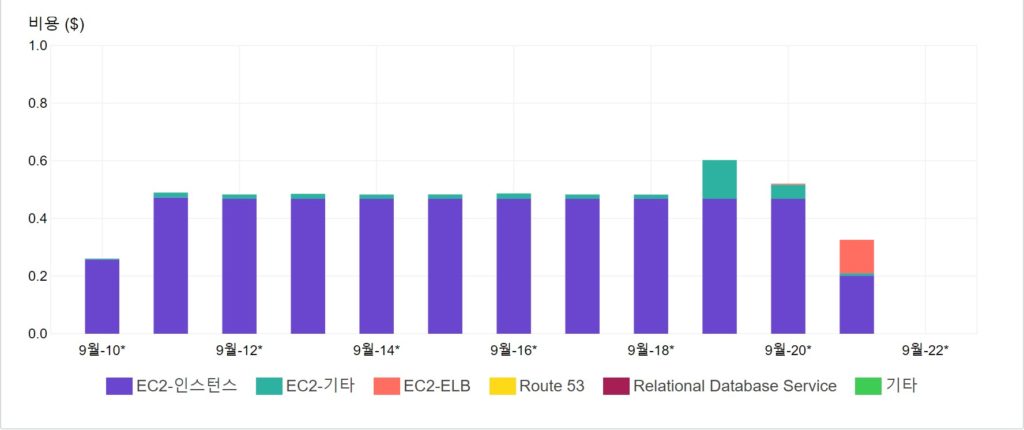
galera cost
rds cost
9$정도의 차이이며 아직 file over 테스트는 진행하지 않았다. multi-AZ활성화 시에 rds 비용이 추가되는것을 생각하면 큰비용은 아니라 생각되지만..기본적으로 multi-AZ로 구성되는 galera의 경우엔 어떤것이 좋다 나쁘다는 아직 결정할수 있느 근거가 부족하였다.
영문
You are building a website that will retrieve and display highly sensitive information to users.
The amount of traffic the site will receive is known and not expected to fluctuate.
The site will leverage SSL to protect the communication between the clients and the web servers.
Due to the nature of the site you are very concerned about the security of your SSL private key and want to ensure that the key cannot be accidentally or intentionally moved outside your environment.
Additionally, while the data the site will display is stored on an encrypted EBS volume, you are also concerned that the web servers’ logs might contain some sensitive information; therefore, the logs must be stored so that they can only be decrypted by employees of your company.
Which of these architectures meets all of the requirements?
A) Use Elastic Load Balancing to distribute traffic to a set of web servers. To protect the SSL private key, upload the key to the load balancer and configure the load balancer to offload the SSL traffic. Write your web server logs to an ephemeral volume that has been encrypted using a randomly generated AES key.
B) Use Elastic Load Balancing to distribute traffic to a set of web servers. Use TCP load balancing on the load balancer and configure your web servers to retrieve the private key from a private Amazon S3 bucket on boot. Write your web server logs to a private Amazon S3 bucket using Amazon S3 server-side encryption.
C) Use Elastic Load Balancing to distribute traffic to a set of web servers, configure the load balancer to perform TCP load balancing, use an AWS CloudHSM to perform the SSL transactions, and write your web server logs to a private Amazon S3 bucket using Amazon S3 server-side encryption.
D) Use Elastic Load Balancing to distribute traffic to a set of web servers. Configure the load balancer to perform TCP load balancing, use an AWS CloudHSM to perform the SSL transactions, and write your web server logs to an ephemeral volume that has been encrypted using a randomly generated AES key.
구글 번역기
매우 민감한 정보를 검색하여 사용자에게 표시하는 웹 사이트를 구축 중입니다.
사이트에서 수신 할 트래픽의 양은 알려져 있으며 변동하지 않을 것으로 예상됩니다.
이 사이트는 SSL을 활용하여 클라이언트와 웹 서버 간의 통신을 보호합니다.
사이트의 특성상 SSL 개인 키의 보안에 대해 매우 우려하고 있으며 실수로 또는 의도적으로 키를 환경 외부로 이동할 수 없도록합니다.
또한 사이트에 표시 할 데이터는 암호화 된 EBS 볼륨에 저장되지만 웹 서버 로그에는 중요한 정보가 포함될 수 있습니다.
따라서 로그는 회사 직원 만 해독 할 수 있도록 저장해야합니다.
이 중 어느 아키텍처가 모든 요구 사항을 충족합니까?
A) Elastic Load Balancing을 사용하여 트래픽을 일련의 웹 서버에 분산시킵니다. SSL 개인 키를 보호하려면 키를로드 밸런서에 업로드하고 SSL 트래픽을 오프로드하도록로드 밸런서를 구성하십시오. 무작위로 생성 된 AES 키를 사용하여 암호화 된 임시 볼륨에 웹 서버 로그를 작성하십시오.
B) Elastic Load Balancing을 사용하여 트래픽을 일련의 웹 서버에 배포합니다. 로드 밸런서에서 TCP로드 밸런싱을 사용하고 부팅시 프라이빗 Amazon S3 버킷에서 프라이빗 키를 검색하도록 웹 서버를 구성하십시오. Amazon S3 서버 측 암호화를 사용하여 웹 서버 로그를 프라이빗 Amazon S3 버킷에 씁니다.
C) Elastic Load Balancing을 사용하여 트래픽을 웹 서버 세트에 분배하고,로드 밸런서가 TCP로드 밸런싱을 수행하도록 구성하고, AWS CloudHSM을 사용하여 SSL 트랜잭션을 수행하고, Amazon을 사용하여 웹 서버 로그를 프라이빗 Amazon S3 버킷에 쓰고 S3 서버 측 암호화를 사용합니다.
D) Elastic Load Balancing을 사용하여 트래픽을 일련의 웹 서버에 분산시킵니다. TCP로드 밸런싱을 수행하고 AWS CloudHSM을 사용하여 SSL 트랜잭션을 수행하고 임의로 생성 된 AES 키를 사용하여 암호화 된 임시 볼륨에 웹 서버 로그를 쓰도록로드 밸런서를 구성하십시오.
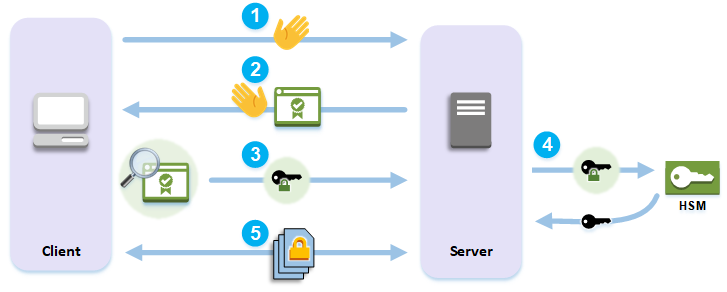
먼저 이문제의 요점을 정리하자면 로그를 암호화 해야되며 어떤 구성이 로그의 암호화를 충족하는지를 물어보는 문제이다. 일단 소거법으로 보자. A는 키를 로드벨런서에 업로드 하였으므로 오답. 또한 ssl offloading은 서버와 클라이언트간 암호화는 아니다. B는 가능한 방법이나 일반적인 방법은 아님. C 는 cloudHSM 이뭔지 부터 알아야 한다. cloudHSM은 문제에서 요구하는 ssl 통신 구성이 가능하다.
이미지를 참고하기 바란다. 따라서 C는 현재 아키텍처의 요구사항에 충족한다. D또한 요구사항에 충족하는데 cloudHSM을 사용하고 임시볼륨에 웹서버 로그를 저장한다. 인스턴스가 재부팅될 경우 데이터가 사라지게 되는데 문제에는 로그의 보관기일이 정해져있거나 로그를 남겨야하는 내용은 없다. 따라서 C/D가 갈리게 된다. 개인적으론 답을 C라고 생각하는데 다른 생각이 있으신 분은 답글을 달아주시기 바란다.
일본판에선 D가 정답이므로 시험에 나오면 D를 선택하는게 좋을것 같다.
영문
You are designing network connectivity for your fat client application. The application is designed for business travelers who must be able to connect to it from their hotel rooms, cafes, public Wi-Fi hotspots, and elsewhere on the Internet. You do not want to publish the application on the Internet. Which network design meets the above requirements while minimizing deployment and operational costs?
A) Implement AWS Direct Connect, and create a private interface to your VPC. Create a public subnet and place your application servers in it.
B) Implement Elastic Load Balancing with an SSL listener that terminates the back-end connection to the application.
C) Configure an IPsec VPN connection, and provide the users with the configuration details. Create a public subnet in your VPC, and place your application servers in it.
D) Configure an SSL VPN solution in a public subnet of your VPC, then install and configure SSL VPN client software on all user computers. Create a private subnet in your VPC and place your application servers in it.
구글 번역기
팻 클라이언트 애플리케이션을위한 네트워크 연결을 설계하고 있습니다. 이 응용 프로그램은 호텔 객실, 카페, 공공 Wi-Fi 핫스팟 및 기타 인터넷에서 연결할 수 있어야하는 비즈니스 여행객을 위해 설계되었습니다. 인터넷에 응용 프로그램을 게시하고 싶지 않습니다. 배포 및 운영 비용을 최소화하면서 위의 요구 사항을 충족하는 네트워크 설계는 무엇입니까?
A) AWS Direct Connect를 구현하고 VPC에 대한 개인 인터페이스를 생성하십시오. 퍼블릭 서브넷을 생성하고 애플리케이션 서버를 그 안에 배치하십시오.
B) 애플리케이션에 대한 백엔드 연결을 종료하는 SSL 리스너를 사용하여 Elastic Load Balancing을 구현합니다.
C) IPsec VPN 연결을 구성하고 사용자에게 구성 세부 정보를 제공하십시오. VPC에 퍼블릭 서브넷을 생성하고 애플리케이션 서버를 퍼블릭 서브넷에 배치하십시오.
D) VPC의 퍼블릭 서브넷에서 SSL VPN 솔루션을 구성한 다음 모든 사용자 컴퓨터에서 SSL VPN 클라이언트 소프트웨어를 설치 및 구성하십시오. VPC에 프라이빗 서브넷을 생성하고 애플리케이션 서버를 배치하십시오.
영문
Your company hosts an on-premises legacy engineering application with 900GB of data shared via a central file server. The engineering data consists of thousands of individual files ranging in size from megabytes to multiple gigabytes. Engineers typically modify 5-10 percent of the files a day. Your CTO would like to migrate this application to AWS, but only if the application can be migrated over the weekend to minimize user downtime. You calculate that it will take a minimum of 48 hours to transfer 900GB of data using your company’s existing 45-Mbps Internet connection. After replicating the application’s environment in AWS, which option will allow you to move the application’s data to AWS without losing any data and within the given timeframe?
A) Copy the data to Amazon S3 using multiple threads and multi-part upload for large files over the weekend, and work in parallel with your developers to reconfigure the replicated application environment to leverage Amazon S3 to serve the engineering files.
B) Sync the application data to Amazon S3 starting a week before the migration, on Friday morning perform a final sync, and copy the entire data set to your AWS file server after the sync completes.
C) Copy the application data to a 1-TB USB drive on Friday and immediately send overnight, with Saturday delivery, the USB drive to AWS Import/Export to be imported as an EBS volume, mount the resulting EBS volume to your AWS file server on Sunday.
D) Leverage the AWS Storage Gateway to create a Gateway-Stored volume. On Friday copy the application data to the Storage Gateway volume. After the data has been copied, perform a snapshot of the volume and restore the volume as an EBS volume to be attached to your AWS file server on Sunday.
구글 번역본
회사는 중앙 파일 서버를 통해 900GB의 데이터를 공유하는 온-프레미스 레거시 엔지니어링 응용 프로그램을 호스팅합니다. 엔지니어링 데이터는 메가 바이트에서 수기가 바이트에 이르는 수천 개의 개별 파일로 구성됩니다. 엔지니어는 일반적으로 하루에 5-10 %의 파일을 수정합니다. CTO는이 애플리케이션을 AWS로 마이그레이션하려고하지만 주말 동안 애플리케이션을 마이그레이션하여 사용자 중단 시간을 최소화 할 수있는 경우에만 해당합니다. 회사의 기존 45Mbps 인터넷 연결을 사용하여 900GB의 데이터를 전송하는 데 최소 48 시간이 소요될 것으로 계산합니다. AWS에서 애플리케이션 환경을 복제 한 후 데이터 손실없이 주어진 기간 내에 애플리케이션 데이터를 AWS로 이동할 수있는 옵션은 무엇입니까?
A) 주말 동안 대용량 파일에 대해 다중 스레드 및 다중 부분 업로드를 사용하여 데이터를 Amazon S3에 복사하고 개발자와 병행하여 Amazon S3를 활용하여 엔지니어링 파일을 제공하도록 복제 된 애플리케이션 환경을 재구성합니다.
B) 마이그레이션 1 주일 전부터 금요일 아침에 최종 동기화를 수행하고 동기화가 완료된 후 전체 데이터 세트를 AWS 파일 서버에 복사하여 애플리케이션 데이터를 Amazon S3에 동기화합니다.
C) 금요일에 애플리케이션 데이터를 1TB USB 드라이브에 복사하고 토요일 배달을 통해 USB 드라이브를 AWS Import / Export로 전송하여 EBS 볼륨으로 가져 오면 결과 EBS 볼륨을 AWS 파일 서버에 마운트합니다. 일요일에.
D) AWS Storage Gateway를 활용하여 게이트웨이 저장 볼륨을 생성합니다. 금요일에 애플리케이션 데이터를 Storage Gateway 볼륨에 복사하십시오. 데이터를 복사 한 후 볼륨의 스냅 샷을 수행하고 일요일에 AWS 파일 서버에 연결할 EBS 볼륨으로 볼륨을 복원하십시오.
이문제는 굉장히 기분이 나쁜 유형의 문제이다. 하지만 마이그레이션 문제로 단골문제인거 같다.
먼저 900G를 aws로 마이그레이션 하는것이다. 45mbps로 이동시간은 2일이다.
A 회선이 느리므로 병목이 발생한다. 멀티파트 업로드가 소용이 없다. 오답이다. B 파일의 변경이 많이 발생하지 않으므로 가능한 방법이다. C의 경우 굉장히 긴가민가 했다. AWS Import/Export Disk는 일부리전에서 사용가능하긴 하나 인터넷을 사용하지 않음으로 병목도 없고 도착시부터 업로드가 시작되어 정상적으로 작업이 진행될것이라 생각했지만 usb 메모리의 속도는 그보다 떨어진다. 그래서 정해진 시간에 마이그레이션이 불가능하다는 결론에 도달했다. 그 결론에 도달한 이유는 '데이터 로드 시간은 기본적으로 디바이스 속도에 의해 좌우' 아래 URL을 참고하기 바란다. https://aws.amazon.com/ko/snowball/disk/faqs/ D AWS Storage Gateway는 네트워크를 이용하므로 동일하게 병목이 발생한다 따라서 오답이다.