이제야 블로그가 손에 잡혀서 오랜만에 글을 쓰기위해 책상앞에 앉았다. 이게다 내 게으름 때문이다.
맨날 이 뻔한 핑계를 치면서 한번 웃고야 말았다.
이번에 쓸 블로깅은 T101에서 한번 발표한 적인 있는 내용이다.
이 포스팅에선 EventBridge와 CloudTrail을 집중적으로 다룬다.
먼저 시작하기전에 EventBridge Bus 규칙에서 Trail에서 패턴을 감지하기위해선 이벤트버스는 무조건 Default여야한다. 다른 버스에 만들면 버스 지나간 다음 손 흔들어야 한다. 패턴을 감지할수 없다는 이야기다.
골자는 이렇다.
CloudTrail 에서 발생하는 이벤트를 EventBridge 는 특정 패턴을 감지해서 이벤트를 발생시킬수 있다.
아래 예가 그렇다.
{
"source": ["aws.iam", "aws.ec2"],
"detail-type": ["AWS API Call via CloudTrail"],
"detail": {
"eventSource": ["iam.amazonaws.com", "ec2.amazonaws.com"],
"eventName": ["AttachGroupPolicy", "AttachRolePolicy", "AttachUserPolicy", "ChangePassword", "CreateAccessKey", "CreateGroup", "CreatePolicy", "CreateRole", "CreateUser", "DeleteAccessKey", "DeleteGroup", "DeleteGroupPolicy", "DeletePolicy", "DeleteRole", "DeleteRolePolicy", "DeleteUser", "DeleteUserPolicy", "DetachGroupPolicy", "DetachRolePolicy", "DetachUserPolicy", "PutGroupPolicy", "PutRolePolicy", "PutUserPolicy", "AuthorizeSecurityGroupIngress", "AuthorizeSecurityGroupEgress", "RevokeSecurityGroupIngress", "RevokeSecurityGroupEgress"]
}
}AWS ec2와 iam에서 발생하는 특정 패턴을 감지하여 이벤트를 발생시키는것이다.
여기에서 내가 굉장히 많은시간 고민을했다. 이유는 패턴 때문이다. 내가 감지하고 싶은 패턴은 AWSConsoleLogin 이다. 이 API가 속하는 source 와 detail-type 이 정리된 곳이 없었기 때문이다. 또한 EventBridge에서 템플릿으로 제공하는 이벤트 패턴으로 테스트했을 땐 잘되지 않았다. 고민했던 부분은 총 3가지 였다.
첫번째로 이벤트 패턴을 감지하기위해서 일반적으로 source 와 detail-type 을 지정해줘야했는데 모든예제는 Source 를 무조건 사용하도록 되어있었다. EventBridge 에선 3가지 이벤트 패턴을 사용할수 있는데 그중 하나만 사용해도 문제가 없다.
source / detail-type / detail 이렇게 세가지이다.
두번째 문제는 Trail에 찍히는 로그와 EventBridge 에 전달되는 이벤트의 내용이 다르다.
{
'version':'0',
'id':'1',
'detail-type':'AWS Console Sign In via CloudTrail',
'source':'aws.signin',
'account':'1',
'time':'2022-12-17T01:09:08Z',
'region':'ap-northeast-2',
'resources':[
],
'detail':{
'eventVersion':'1.08',
'userIdentity':{
'type':'IAMUser',
'principalId':'1',
'accountId':'1',
'accessKeyId':'',
'userName':'1'
},
'eventTime':'2022-12-17T01:09:08Z',
'eventSource':'signin.amazonaws.com',
'eventName':'CheckMfa',
'awsRegion':'ap-northeast-2',
'sourceIPAddress':'58.227.0.134',
'userAgent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/106.0.5249.114 Safari/537.36', 'requestParameters':None,
'responseElements':{
'CheckMfa':'Success'
},
'additionalEventData':{
'MfaType':'Virtual MFA'
},
'eventID':'1',
'readOnly':False,
'eventType':'AwsConsoleSignIn',
'managementEvent':True,
'recipientAccountId':'1',
'eventCategory':'Management',
'tlsDetails':{
'tlsVersion':'TLSv1.2',
'cipherSuite':'ECDHE-RSA-AES128-GCM-SHA256',
'clientProvidedHostHeader':'ap-northeast-2.signin.aws.amazon.com'
}
}
}{
"eventVersion": "1.08",
"userIdentity": {
"type": "IAMUser",
"principalId": "1",
"arn": "arn:aws:iam::1:",
"accountId": "1",
"accessKeyId": ""
},
"eventTime": "2022-12-17T02:29:28Z",
"eventSource": "signin.amazonaws.com",
"eventName": "ConsoleLogin",
"awsRegion": "ap-northeast-2",
"sourceIPAddress": "58.227.0.134",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.5249.207 Safari/537.36",
"requestParameters": null,
"responseElements": {
"ConsoleLogin": "Success"
},
"additionalEventData": {
"LoginTo": "https://ap-northeast-2.console.aws.amazon.com/console/home?hashArgs=%23&isauthcode=true®ion=ap-northeast-2&state=hashArgsFromTB_ap-northeast-2_b149694953e40e5b",
"MobileVersion": "No",
"MFAIdentifier": "arn:aws:iam::1:mfa/root-account-mfa-device",
"MFAUsed": "Yes"
},
"eventID": "1",
"readOnly": false,
"eventType": "AwsConsoleSignIn",
"managementEvent": true,
"recipientAccountId": "1",
"eventCategory": "Management",
"tlsDetails": {
"tlsVersion": "TLSv1.2",
"cipherSuite": "1",
"clientProvidedHostHeader": "signin.aws.amazon.com"
}
}민감 정보는 지웠다. 이렇게 두가지 내용이 다르다. 처음에 Trail Log를 보고서 패턴을 작성하다가 놀랐다. 그리고 이 이벤트를 보려면 이벤트 브릿지에선 넘어온 데이터를 볼수없다. 이벤트 카운트 뿐이다.
세번째는 리전에 대한 이야기다.
우리의 Console 로그인은 리전기반이다. 이게 나를 오랜시간 고민하게 하고 괴롭혔다.
Trail은 글로벌 서비스 이벤트가 있다.

이 글로벌 서비스중 sts에 우리는 주목해야한다. 로그인할때 STS 를 호출하기 때문이다. 그럼 STS 를 설명하기 전에 Console Login 부터 알아야한다.
로그인을 시도할때 우리는 AWS Console 을 통해 그냥 로그인한다고 생각하지만, 그렇지 않다. AWS Console은 로그인 할때 이런 URL 을 가지고 있다.
https://signin.aws.amazon.com/signin?redirect_uri=https%3A%2F%2Fconsole.aws.amazon.com%2Fconsole%2Fhome%3FhashArgs%3D%2523%26isauthcode%3Dtrue%26state%3DhashArgsFromTB_ap-northeast-1_6b240714978b3994&client_id=arn%3Aaws%3Asignin%3A%3A%3Aconsole%2Fcanvas&forceMobileApp=0&code_challenge=U8A4YkTPRIIvi-8Gj7-tIx4RB_PR9IT-4fVs7diVUoc&code_challenge_method=SHA-256
이 URL로 로그인하면 Console Login log는 ap-northeast-1 로 연결된다. 그러니까 우리는 도쿄로 연결되는 로그인때문에 이것을 재대로 트래킹 할수 없다는 이야기다. 놓치는 로그인들을 해결하고 싶었다.
글로벌 서비스를 추적하면 도쿄로 연결되는 로그인을 추적할수 있을까?
정답은 "그렇다" 하지만 문제가 생길수도 있다.
슬프게도 글로벌서비스 추적이란 그냥 글로벌 엔드포인트를 이용하면 그 로그가 us-east-1 에 쌓일 뿐 모든 리전의 STS로그가 글로벌서비스 추적에 쌓이는건 아니다.
그렇기에 로그인 추적은 어렵다. 그렇다고 해서 아주 못하는것은 아니다. 로그인은 반드시 STS를 호출한다. 극단적으로 가기로 했다.
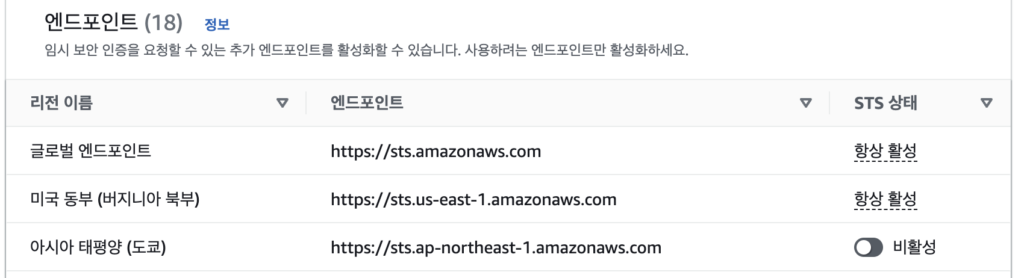
위에서 로그인 URL에 도쿄리전으로 파라미터가 들어가있는데 그 대로 로그인 해보겠다. 그전에 나의 계정에선 도쿄의 STS 엔드포인트를 비활성화하였다.
{
"eventVersion": "1.08",
"userIdentity": {
"type": "1",
"principalId": "1",
"arn": "arn:aws:iam::1:1",
"accountId": "1",
"accessKeyId": ""
},
"eventTime": "2022-12-17T04:02:18Z",
"eventSource": "signin.amazonaws.com",
"eventName": "ConsoleLogin",
"awsRegion": "us-east-1",
"sourceIPAddress": "1",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
"requestParameters": null,
"responseElements": {
"ConsoleLogin": "Success"
},
"additionalEventData": {
"LoginTo": "https://console.aws.amazon.com/console/home?hashArgs=%23&isauthcode=true&state=hashArgsFromTB_ap-northeast-1_6b240714978b3994",
"MobileVersion": "No",
"MFAIdentifier": "arn:aws:iam::1:mfa/1-account-mfa-device",
"MFAUsed": "Yes"
},
"eventID": "1",
"readOnly": false,
"eventType": "AwsConsoleSignIn",
"managementEvent": true,
"recipientAccountId": "1",
"eventCategory": "Management",
"tlsDetails": {
"tlsVersion": "TLSv1.2",
"cipherSuite": "ECDHE-RSA-AES128-GCM-SHA256",
"clientProvidedHostHeader": "signin.aws.amazon.com"
}
}로그 보면 이렇다. LoginTo 에서는 ap-northeast-1 로 로그인했으나, 실제 리전은 us-east-1 로 연결되었다. 글로벌서비스 STS로 연결된것이다. 아마 가까운 리전엔드포인트를 제공해주는것으로 보는데 실제로는 잘모른다.
이렇게 세가지의 고민을 끝내고 Trail의 추적을 생성하였는데, 문제를 찾을수 있었다.
우리는 필연적으로 버지니아 북부와 실제사용리전에서 Trail의 추적을 생성해야하는데 이걸 콘솔에선 생성해선 안된다.
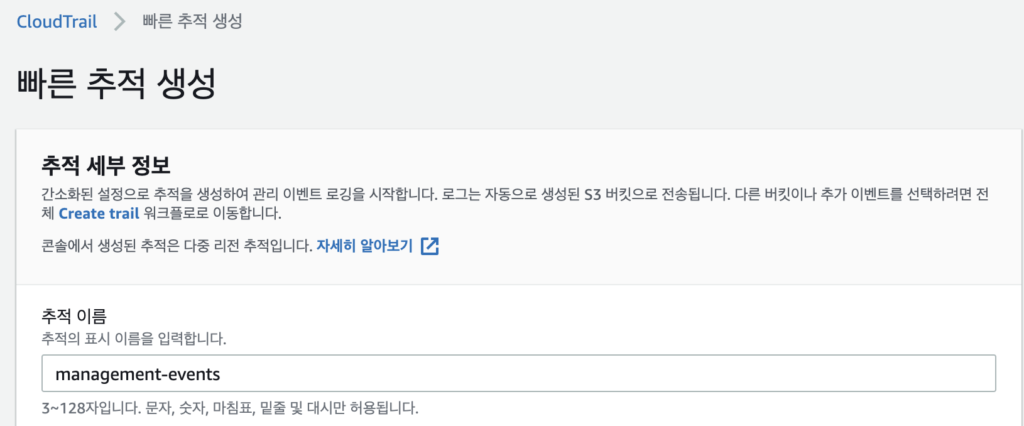
이전에는 Trail 에서는 콘솔에서 다중추적의 온오프를 옵션으로 제공했는데 이젠 그렇지 않다. 이전의 기억만 믿고 진행했다가 다중추적이 여러군데 생성되었다.
https://aws.amazon.com/ko/premiumsupport/knowledge-center/remove-duplicate-cloudtrail-events/
다중추적의 중복은 비용이 발생한다.
PaidEventsRecorded 이 지표가 증가한다면 다중추적이 여러개가 생성된거다.
그렇기에 추적을 생성할땐 주요사용리전에만 다중리전 추적을 생성하고 버지니아 북부에서는 글로벌서비스 추적만 활성화 해야한다. 그러면 비용이 추가되지 않는다.
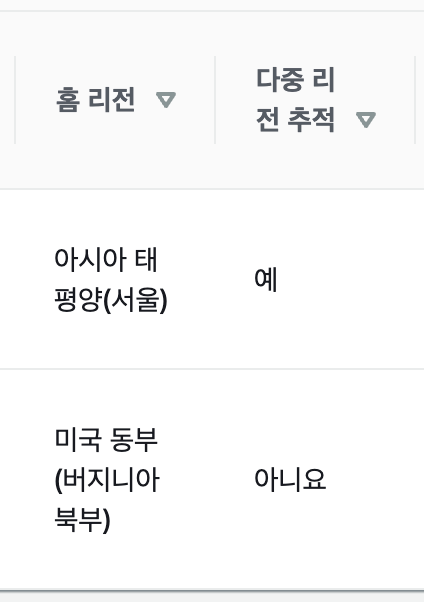
글로벌 서비스 추적을 만들려면 AWSCLI를 이용해서 만들어야 한다.
# aws cloudtrail update-trail --name my-trail --no-include-global-service-eventsEventBridge 와 Trail에 대한 삽질기를 이렇게 정리해둔다.
조금이나마 도움이 되길 빈다.