블로그를 새로 만들기로 했다.
https://linuxer.name/2020/02/aws-linuxer의-블로그-톺아보기
2020년 2월에 완성된 블로그의 구조이니..이걸 우려먹은지도 벌써 1년이 훌쩍넘어다는 이야기다. 블로그를 좀더 가볍고 편한구조로 변경하려고 고민했으나..나는 실패했다.ㅠㅠ
능력이나 뭐 그런 이야기가 아니라..게으름에 진거다. 게으름에 이기기 위해서 글을 시작했다.
목적은 K8S 에 새로 만들기고, K8S의 특성을 가져가고 싶었다.
제일먼저 작업한것은 Wordpess 의 근간이 되는 PHP 다.
PHP는 도커파일을 먼저 작성했다.
FROM php:7.4-fpm
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
libpng-dev \
libzip-dev \
libicu-dev \
libzip4 \
&& pecl install xdebug \
&& docker-php-ext-install opcache \
&& docker-php-ext-enable xdebug \
&& docker-php-ext-install pdo_mysql \
&& docker-php-ext-install exif \
&& docker-php-ext-install zip \
&& docker-php-ext-install gd \
&& docker-php-ext-install intl \
&& docker-php-ext-install mysqli
# Clear cache
RUN apt-get clean && rm -rf /var/lib/apt/lists/*
WORKDIR /srv/app
RUN cp /usr/local/etc/php/php.ini-production /usr/local/etc/php/php.ini
RUN echo "date.timezone=Asia/Seoul" >> /usr/local/etc/php/php.ini
RUN sed -i --follow-symlinks 's|127.0.0.1:9000|/run/php-fpm.sock|g' /usr/local/etc/php-fpm.d/www.conf
RUN sed -i --follow-symlinks 's|short_open_tag = Off|short_open_tag = On|g' /usr/local/etc/php/php.ini
RUN sed -i --follow-symlinks 's|9000|/run/php-fpm.sock|g' /usr/local/etc/php-fpm.d/zz-docker.conf
CMD ["php-fpm"]몇가지 수정사항이 있었는데 먼저 tcp socket를 사용하지 않고, unix socket을 사용했다. 흔하게 file socket이라고도 하는데 nginx <-> php-fpm 의 socket 통신의 속도가 상승한다. nginx와 php-fpm이 같은 서버내에 있을때 사용할수 있는 방법이다.
또 zz-docker.conf 는 php 이미지에서 ext를 설치할때 docker 패키지를 사용하면설치되는데 이 conf파일안에 unix 소켓을 사용할수 없도록 만드는 설정이 있다.
[global] daemonize = no [www] listen = 9000
위설정이 바로 그 설정이다 listen = 9000 이 fix로 박히게 되는데 이걸 수정해주지 않으면 www.conf를 아무리 수정해도 unix socket을 사용할수 없다. 변경하고 빌드는 정상적으로 됬다.
빌드후 push는 NCP 의 Container Registry 서비스를 이용했다. docker login 할때 sub account 의 access key 와 secret key를 생성해서 사용했다.
docker build -t linuxer-cr/php-fpm:12 ./ docker push linuxer-cr/php-fpm:12
12번에 걸쳐서 빌드 테스트를 진행했다. centos 이미지였다면 쉬웠을껀데ㅠㅠ그냥 있는 이미지 써본다고 고생했다. 빌드가 완료된 php-fpm을 deployment 로 배포했다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-fpm-nginx-deployment
spec:
selector:
matchLabels:
app: php-fpm-nginx
template:
metadata:
labels:
app: php-fpm-nginx
spec:
imagePullSecrets:
- name: regcred
containers:
- name: php-fpm
image: linuxer-rc/php-fpm:12
volumeMounts:
- name: vol-sock
mountPath: /run
- name: www
mountPath: /usr/share/nginx/html
- name: nginx
image: nginx:1.21
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "chmod 777 /run/php-fpm.sock"]
volumeMounts:
- name: vol-sock
mountPath: /run
- name: nginx-config-volume
mountPath: /etc/nginx/conf.d/default.conf
subPath: default.conf
- name: www
mountPath: /usr/share/nginx/html
volumes:
- name: vol-sock
emptyDir:
medium: Memory
- name: nginx-config-volume
configMap:
name: nginx-config
- name: html
emptyDir: {}
- name: www
persistentVolumeClaim:
claimName: nfs-pvc위의 manifest 는 완성된 버전이다. 특이한 부분을 말하자면 몇가지가 있는데,
첫번째로 nignx pod 와 php-fpm container의 unix socket 을 공유하는 부분이다.
emptyDir: medium:Memory 로 지정하면 메모리를 emptydir 로 사용한다 원래 컨셉은 shm 을 hostpath로 이용하여 마운트해서 사용하려했는데 편리한 방법으로 지원해서 사용해봤다. 일반 디스크에 unix socket를 사용하는것보다 속도가 빠를것이라 예상한다
벤치를 돌려보기엔 너무 귀찮았다.
두번째로 lifecycle: postStart다. nginx 프로세스가 시작하면서 소켓을 생성하기에 권한부족으로 정상적으로 php-fpm과 통신이 되지 않았다. 그래서 lifecycle hook을 이용하여 컨테이너가 모두 생성된 이후에 cmd 를 실행하도록 설정하였다.
세번째로 여러개의 파드에서 같은 데이터를 써야하므로 고민을 했다.
NFS-Server pod 를 생성하여 내부에서 NFS-Server를 이용한 데이터를 공유하느냐, 아니면 NAS서비스를 이용하여 NFS Client provisioner 를 이용할것인가. 고민은 금방 끝났다.
편한거 쓰자! NAS를 사용했다.

NAS 서비스를 확인하고,
#프로비저너 설치
helm --kubeconfig=$KUBE_CONFIG install storage stable/nfs-client-provisioner --set nfs.server=169.254.82.85 --set nfs.path=/n2638326_222222
#프로비저너 설치확인
k get pod storage-nfs-client-provisioner-5b88c7c55-dvtlj
NAME READY STATUS RESTARTS AGE
storage-nfs-client-provisioner-5b88c7c55-dvtlj 1/1 Running 0 33m
#nfs-pvc 설치
cat << EOF | k apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: nfs-client
EOF볼륨까지 프로비저닝했다.
그리고 네번째 nginx-config 다 configmap 으로 만들어져서 /etc/nginx/conf.d/default.conf 경로에 subpath 로 파일로 마운트된다.
cat << EOF | k apply -f -
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-config
data:
default.conf: |
server {
root /usr/share/nginx/html;
listen 80;
server_name _;
#access_log /var/log/nginx/host.access.log main;
location / {
index index.php;
try_files \$uri \$uri/ /index.php?\$args;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
location ~ [^/]\.php(/|$) {
fastcgi_split_path_info ^(.+?\.php)(/.*)$;
fastcgi_pass unix:/run/php-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param REQUEST_METHOD \$request_method;
fastcgi_param SCRIPT_FILENAME \$document_root\$fastcgi_script_name;
}
}
EOF나는 대다수의 manifest를 shell 에서 그대로 적용해버리기때문에 $request_method 이런 변수가 있는 부분은 \$request_method 역슬러시를 넣어서 평문 처리를해줬다.
이 nginx conf configmaps 에서 특이점은 try_files \$uri \$uri/ /index.php?\$args; 부분이다. 이부분이 빠지면 wordpress 의 주소형식을 사용할수 없어 페이지 이동이 되지 않는다.
이제 이 모든과정이 php-fpm-nginx-deployment 를 정상적으로 동작하게 하기위한 과정이었다.
이제 데이터를 AWS 에 있는 EC2 에서 가져왔다.
그냥 귀찮아서 bastion host에서 rsync 로 sync 했다.
#NFS mount mount -t nfs nasserverip/마운트정보 /mnt #pod 가 마운트된 pvc로 다이렉트로 sync rsync root@aws-ec2-ip:/wordpressdir /mnt/default-nfs-pvc-pvc-d04852d6-b138-40be-8fc3-150894a3daac
이렇게 하니 단순 expose 만으로도 1차적으로 사이트가 떴다.
NPLB(Network Proxy Load Balancer) -> nginx-php-fpm POD -> AWS RDS
이런구성으로 돌고있었기에 DB를 옮겨왔다.
#mysqldump mysqldump -h rdsendpoint -u linxuer -p linuxer_blog > linuxerblog.sql #sync rsync root@aws-ec2-ip:/linuxerblog.sql /home/
테스트용도로 사용할 CDB

mysql -h cdb-endpoint -u -p linuxer_blog < linuxerblog.sql
디비 복구후 wp-config 에서 define('DB_HOST') 를 CDB로 변경했다. 기나긴 트러블 슈팅의 기간이 끝나가고 있었다.
잘될줄 알았는데, 그건 저 혼자만의 생각이었습니다.
처음부터 SSL은 절대 처리하지 않을것이라 생각했건만...이렇게 된거 Let's encrypt로 간다!
#certbot install yum install certbot certbot-plagin-route53 #route53이용한 인증 certbot certonly \ --dns-route53 \ -d linuxer.name \ -d *.linuxer.name
인증서에 root ca 가 포함되어있지 않기 때문에 root ca를 서버의 번들 인증서에서 삽입해 줘야한다.
openssl pkcs7 -inform der -in dstrootcax3.p7c -out dstrootcax3.pem -print_certs cp fullchain.pem fullca.pem cat dstrootcax3.pem >> fullca.pem openssl verify -CAfile fullca.pem cert.pem cert.pem: OK
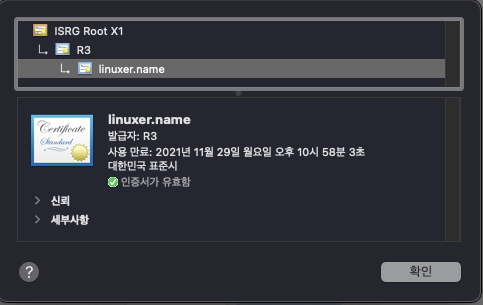
이렇게 하면 이제 private key, public key, root ca chain 해서 Certificate Manager에 인증서가 등록이 가능하다. 여기에 잘 등록하면,

이렇게 인증서를 등록할수 있다. 인증서의 발급기관은 R3로 뜬다.
이제 드디어 ingress 를 만들 준비가 되었다. ingress 를 만들기 위해 먼저 svc가 필요하다.
k expose deployment php-fpm-nginx-deployment --type=NodePort --port=80 --target-port=80 --name=php-fpm-nginx-deployment k get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE php-fpm-nginx-deployment-svc NodePort 198.19.196.141 <none> 80:30051/TCP 24h
정상적으로 만들어 진게 확인되면,
cat << EOF | k apply -f -
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80},{"HTTPS":443}]'
alb.ingress.kubernetes.io/ssl-certificate-no: "----"
alb.ingress.kubernetes.io/actions.ssl-redirect: |
{"type":"redirection","redirection":{"port": "443","protocol":"HTTPS","statusCode":301}}
labels:
linuxer: blog
name: slinuxer-blog-ingress
spec:
backend:
serviceName: php-fpm-nginx-deployment-svc
servicePort: 80
rules:
- http:
paths:
- path: /*
backend:
serviceName: ssl-redirect
servicePort: use-annotation
- path: /*
backend:
serviceName: my-service
servicePort: 80
EOF대망의 ingress다. ALB 컨트롤러를 이용해 ingress를 생성하고 컨트롤한다.alb.ingress.kubernetes.io/ssl-certificate-no: "----" 이부분은 Resource Manager에서 NRN을 확인하자.
이후 내블로그를 NKS로 완벽하게 이전을 마치고 앞으로의 K8S의 테스트 환경이 될 모르모트로 완성되었다.
이이후 Route53에서 DNS를 돌리고 자원을 하나씩 중지했다.
입사후 긴시간 동안 마음만 먹었던 프로젝트를 끝내서 너무 속이 시원하다.
이제 NKS위에서 전보다 나은 퍼포먼스를 보여줄 LINUXER BLOG를 응원해 주시라!
즐거운 밤이 되시길 빈다.