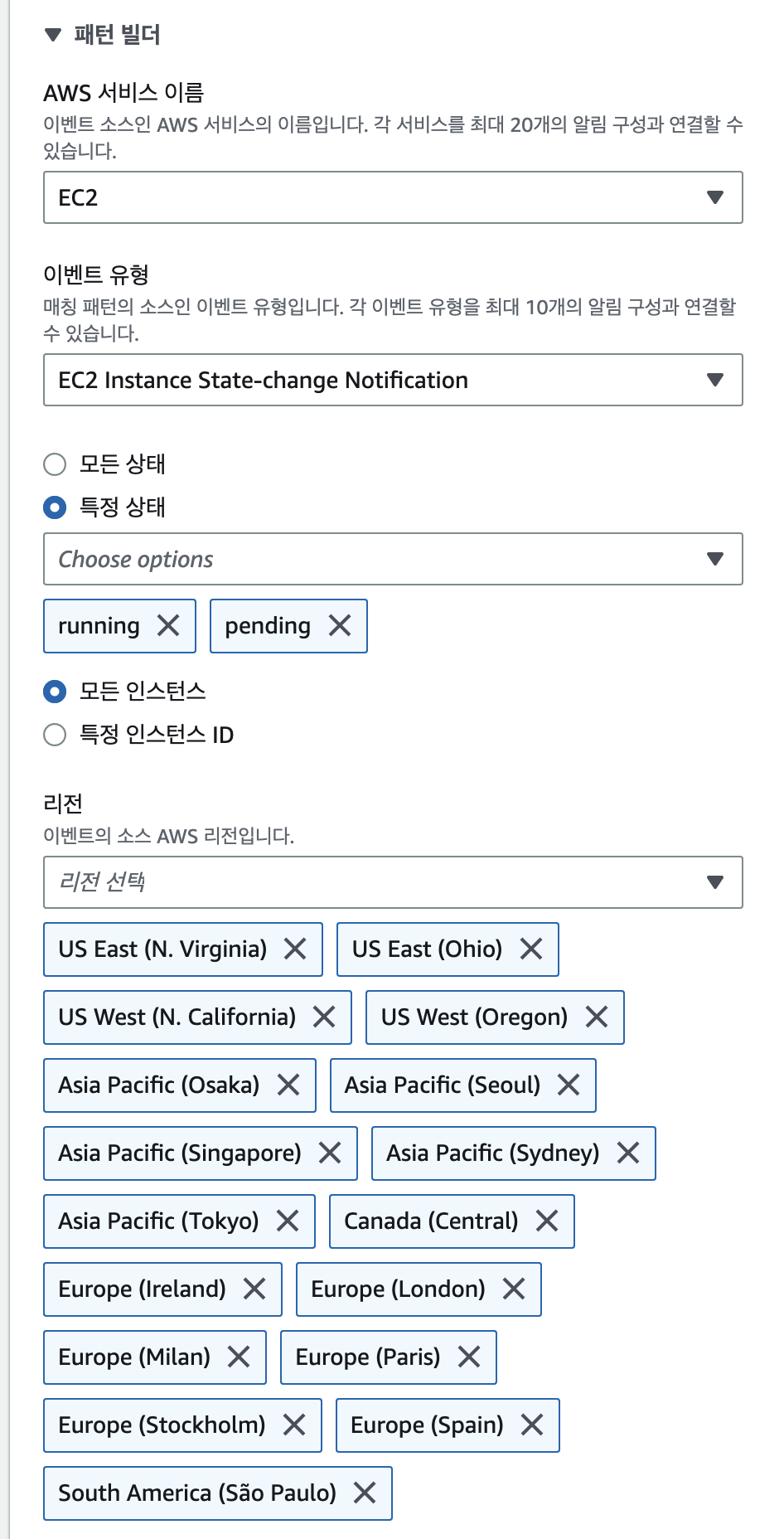
helm install sentry sentry/sentry
coalesce.go:175: warning: skipped value for kafka.config: Not a table.
coalesce.go:175: warning: skipped value for kafka.zookeeper.topologySpreadConstraints: Not a table.
W1023 08:00:35.276931 15594 warnings.go:70] spec.template.spec.containers[0].env[39]: hides previous definition of "KAFKA_ENABLE_KRAFT"
Error: INSTALLATION FAILED: failed post-install: 1 error occurred:
* job failed: DeadlineExceededjob failed: DeadlineExceeded 에러가 발생한다.
이 job은 DB가 정상적으로 올라왔는지 확인하는 job이다.
k get job
NAME COMPLETIONS DURATION AGE
sentry-db-check 0/1 5m23s 5m23s이 Job은 다음을 검증한다.
name: sentry-db-check
namespace: sentry
resourceVersion: "4700657"
uid: 12533bba-b35b-4b7d-9007-8c625b389a98
spec:
activeDeadlineSeconds: 1000
backoffLimit: 6
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
batch.kubernetes.io/controller-uid: 12533bba-b35b-4b7d-9007-8c625b389a98
suspend: false
template:
metadata:
creationTimestamp: null
labels:
app: sentry
batch.kubernetes.io/controller-uid: 12533bba-b35b-4b7d-9007-8c625b389a98
batch.kubernetes.io/job-name: sentry-db-check
controller-uid: 12533bba-b35b-4b7d-9007-8c625b389a98
job-name: sentry-db-check
release: sentry
name: sentry-db-check
spec:
containers:
- command:
- /bin/sh
- -c
- |
echo "Checking if clickhouse is up"
CLICKHOUSE_STATUS=0
while [ $CLICKHOUSE_STATUS -eq 0 ]; do
CLICKHOUSE_STATUS=1
CLICKHOUSE_REPLICAS=3
i=0; while [ $i -lt $CLICKHOUSE_REPLICAS ]; do
CLICKHOUSE_HOST=sentry-clickhouse-$i.sentry-clickhouse-headless
if ! nc -z "$CLICKHOUSE_HOST" 9000; then
CLICKHOUSE_STATUS=0
echo "$CLICKHOUSE_HOST is not available yet"
fi
i=$((i+1))
done
if [ "$CLICKHOUSE_STATUS" -eq 0 ]; then
echo "Clickhouse not ready. Sleeping for 10s before trying again"
sleep 10;
fi
done
echo "Clickhouse is up"
echo "Checking if kafka is up"
KAFKA_STATUS=0
while [ $KAFKA_STATUS -eq 0 ]; do
KAFKA_STATUS=1
KAFKA_REPLICAS=3
i=0; while [ $i -lt $KAFKA_REPLICAS ]; do
KAFKA_HOST=sentry-kafka-$i.sentry-kafka-headless
if ! nc -z "$KAFKA_HOST" 9092; then
KAFKA_STATUS=0
echo "$KAFKA_HOST is not available yet"
fi
i=$((i+1))
done
if [ "$KAFKA_STATUS" -eq 0 ]; then
echo "Kafka not ready. Sleeping for 10s before trying again"
sleep 10;
fi
done
echo "Kafka is up"
image: subfuzion/netcat:latest
imagePullPolicy: IfNotPresent
name: db-check
resources:
limits:
memory: 64Mi
requests:
cpu: 100m
memory: 64Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Clickhouse / Kafka 가 실행되어야 job은 정상화 가능하다. 시간이 오래걸리는 작업이므로, hook 의 시간을 늘려주면 job은 더 긴시간 대기한다 helm 의 values.yaml 에서 activeDeadlineSeconds를 늘려주면 된다.
hooks:
enabled: true
removeOnSuccess: true
activeDeadlineSeconds: 1000이 시간을 늘려도 문제가 생긴다면 보통 kafka의 pv가 생성되지 않는경우다.
CSI 컨트롤러를 확인해 보는게 좋다.