이글은 Argo Roullouts 의 scaleDownDelaySeconds 옵션부터 preStop terminationGracePeriodSeconds 까지의 과정을 다룬다.
Argo Rollouts 는 배포를 도와주는 툴로 블루그린 카나리등과 같은 부분을 도와주는 도구이다. 간략하게 동작을 설명하겠다.
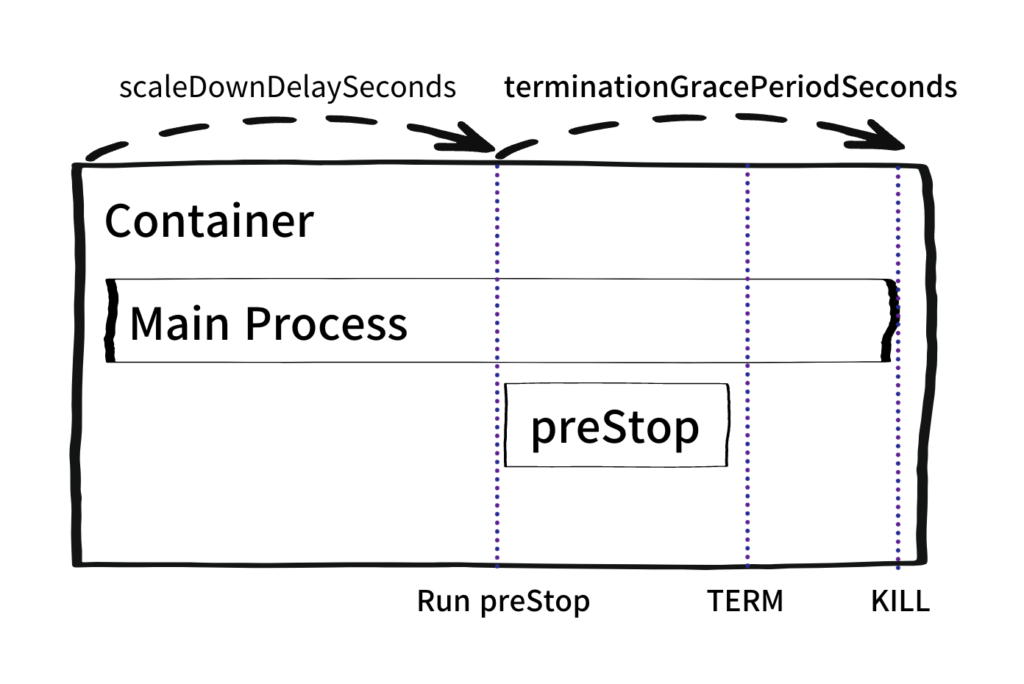
블루그린이 완료된이후 RS는 축소하지 않고 30초간 대기한다. 이 30초간 대기하는 옵션이 scaleDownDelaySeconds다. 혹시나모를 롤백 상황에 대해서 기다리는 옵션인것이다. 이시간이 종료되면 이제 RS는 replicas 를 0으로 수정해서 pod 들은 축소된다.
replicas 가 0으로 수정되면 pod는 일반적인 pod 의 lifecycle 를 거친다. pod 는 여러 차례 말했지만 N+1개의 컨테이너의 집합이고 컨테이너는 프로세스이므로 프로세스의 종료 과정이 그대로 pod 의 lifecycle 를 따르나 쿠버네티스는 이 프로세스를 컨트롤하는 고도화된 툴이므로 다양한 과정을 컨트롤 할수있게 만들어져 있다.
pod 의 종료과정에는 여러 작업을 끼워넣을수 있으며 그 과정중의 하나가 preStop hook 이다. preStop Hook이 설정되면 preStop hook 이 끝날때까지 컨테이너는 종료되지않으며 PreStop 훅이 종료된 시점에 TERM 을 날린다. 그리고terminationGracePeriodSeconds 은 pod 가 종료되는 시점부터 설정된 시간이 끝나면 KILL 시그널을 날린다.
결론적으로 preStop HooK은 terminationGracePeriodSeconds 보다 클수 없다. terminationGracePeriodSeconds 시간내에 행해져야 하고, preStop Hook 보다 커야지만 Graceful 하게 동작할수있다.
인간의 빅데이터는 잘 틀리지 않는다. 보통 그것을 우리는 본능이라 한다. 나의 본능은 2022년부터 위험신호를 보냈다.
나는 인지했지만 충분히 내 능력이라면 이겨낼수 있을거라 생각했다. 그건 내가 잘못 생각한것이었다. 일과 사람은 뗄수없으며, 사람의 문제는 조직의 문제로 발전하고, 건강할수 없다.
그렇지만 나는 최선을 다했다.
그 최선은 나의 마음을 갈아넣는 것이었고, 내 마음 또한 한계가 오는 시점들이 있었다. 이 시점들을 지나고 보니 그게 나는 슬럼프인걸 알았다. 사람은 변하지 않고, 나는 타인을 변하게 할수 없음을 안다. 사람이 변하지 않으면 조직이 변하지 않고, 나는 조직을 변화시킬수 없음을 슬럼프가 다가 왔을때 느꼈다.
그런데도 불구하고 나는 올해 정말 많은 일을 했다.
먼저 회사에서 멀티미디어를 서빙할때 Multi DRM을 사용하는데, 이 Multi DRM의 아키텍처를 내가 설계했다.
E-book 이라는 컨텐츠또한 DRM을 사용하는데 이 DRM을 고도화 하는 작업에서 누구도 납품받은 솔루션을 재대로 다룰수 없는 상태라 이 DRM을 설계하고 프로토 타입을 내가 만들었다. 이 기사 에서 말하는 DRM이 내가 만든거다. 그 다음으로 회사의 인프라는 많은 변화를 겪고있는데, DX를 통하여 서버기반의 인프라를 컨테이너 기반으로 이동중이다. 새로이 만들고 있는 플랫폼은 Gitops / Terraform / EKS 등등 맛있는 건 다들어가있고, 반년이상 지속적으로 관리하고 고도화하는 과정에서 결과물이 슬슬 나오고 있다.
또 팀의 리더로서 나의 동료들을 지키고 성장시키기 위해서 다양한 고민을 했다.
2022년은 같이 일하는 동료를 파악하기 위한 과정이었고, 2023년은 나의 동료들이 최고의 퍼포먼스를 낼수있도록 만드는 과정에 있었다. 그 과정에서 나는 많은 고통을 받았다. 하지만 내 동료들은 정말 많은 성장을 했다.
우리의 형 T. 나는 많은 DBA를 본건아니지만 이토록 방대한 범위를 꼼꼼하게 설계하는 사람을 본적이 없다. 차근차근 항상 꾸준하게 퍼포먼스를 뽑는다. 체계를 만들고 그 체계를 잘 활용한다. 이 과정에서 나오는 시너지가 어마어마 하다. 창의적으로 일하고 업무에 미학이 있다. 아름다운 데이터베이스 아키텍처를 설계한다.
동료인 S. 는 이제 시니어에 이르러서 막강한 퍼포먼스를 뽑아주기 시작했다. 나와는 결이 좀 다른데, 나는 레거시는 뜯어서 없애버리자는 주의인데, 이 동료는 레거시가 분포되어있는 영역을 파악하고 하나로 모아서 고도화 하는 작업을 스스로 시작했다. 또한 누구나 기피하는 운영의 영역에서 단한번도 싫은 내색없이 묵묵히 운영업무를 감내했다. 우리 팀의 최고의 인싸이자 로멘티스트로 정말 멋진 사람이다.
우리의 행동대장 칼잡이 D. 막내인데도 이미 두세사람 몫은 반드시한다. 협업능력 / 판단능력 다 좋다. 업무를 깔끔히 정리하고 이해안되면 죽어라 공부해온다. 그냥 적당히 설명만 하면 납득하거나 납득 안되는 부분은 물어온다. 나로서는 한가지 방식의 지시만 하면된다. 내가 생각하는 목적지를 구체적으로 보여주는것. 구체적인 그림을 보여주거나 내가 예측하는 그림을 보여주기 어려운 경우도 있지만 서로가 생각하는 방식이 비슷한점이 있어서 거의 대부분을 해결했다.
팀 전체로 우리는 올해 같은 목적을 가지고 뛰었고, 같이 분노하고 기뻐했다. 우리가 얻은 가장 큰것은 결속이 아닌가 싶다.
나는 여러번 리더로서 일했지만 성장하는 법을 이제야 배우고 있다.
다시 나의 이야기로 돌아가서 나는 이 과정에서 성장도 경험했지만, 나 스스로 무언가 억눌리고 심리적인 불안감이 있었다. 그건 슬럼프였고, 어느 순간 갑자기 슬럼프가 사라졌다. 그 결과 나는 다시한번 나의 한계를 부술수있는 강한 고양감을 느끼고 있다.
한 해의 마지막에서서 각성이 된다는건 참으로 이상한 일이다. 다른사람들이 마무리와 시작을 준비할때 나는 막 달리고 있는 순간이다. 이 감을 잃지않고 달려보려 한다.
첫번째 시험.. 합격일줄알았는데..떨어졌다.ㅋㅋㅋㅋ 이럴수가ㅋㅋㅋㅋㅋㅋ경악을 금치못했고 공부는 또 안했다. 시험보면서 내가 Docs 에서 원하는 기능이 어디에 있는지 찾는 과정일 뿐 이었기 때문에 그냥 잘 검색하는 방법 yaml 을 좀더 빨리 만들수있게 예제가 있는 위치만 더 찾아봤다.
바로 다시 16일에 시험을 봤고, 합격했다.
고득점일줄 알았는데 나중에 복기해보니 틀린게 좀 있었다.
먼저 Cronjob 은 이제 완전히 옵션을 다 알았다. SecurityContext는 뭐 그럭저럭.. Docker save 명령어는 생각이 안나서 man docker 해서 봤다. Readiness 는 httpget이 Docs엔 안나와있는데 나중에 찾아보니 그냥 공통 구조체더라.
ps -eLf 명령어는 중요한부분은 L 옵션입니다. 스레드를 출력하는 옵션입니다. 그다음 명령어는 httpd 스레드의 2번째 행만 발라낸뒤 숫자로 정렬하고 유니크 명령어로 각 카운트를 세었습니다. 뭔가 연관성이 보이지 않나요? 6번째 행에서 보여주는 값이 프로세스내 스레드 갯수입니다.
이렇게 하나의 프로세스는 여러개의 스레드를 가지고있는 것을 확인할수 있습니다.
그럼 시작하는 엔지니어의 글을 작성한다고 했던 제가 왜 스레드니 프로세스니 하는 이야기를 하고 있을까요?
프로세스는 오늘 할 이야기의 시작이자 끝이기 때문입니다.
프로세스의 정의는 실행 중인 프로그램의 인스턴스입니다. 이는 코드, 데이터, 스택, 힙과 같은 메모리 영역, 파일 디스크립터, 환경 설정 등을 포함합니다. 운영 체제에서 기본적인 실행 단위로, 시스템 자원과 작업을 관리하는 데 사용됩니다.
이 프로세스를 격리하는 메커니즘을 Namespace 라고 합니다. 네임스페이스는 리눅스에서 프로세스를 격리하는 메커니즘입니다. 각 네임스페이스는 특정 종류의 시스템 자원을 감싸고, 프로세스가 그 자원을 별도로 보도록 합니다. 예를 들어, 네트워크, 파일시스템 마운트 포인트, 사용자 ID 등이 있습니다.
마지막으로 Cgroup 는 프로세스 그룹의 시스템 자원 사용을 제한하고 격리하는 기능을 제공합니다. cgroups를 사용하면 CPU 시간, 시스템 메모리, 네트워크 대역폭 등의 자원을 제어할 수 있습니다. 시스템 자원의 공정한 분배 및 특정 프로세스 그룹의 자원 사용을 제한하여 시스템의 안정성을 보장하는 데 사용됩니다.
Namespace, Cgroup 이 둘은 함께 사용되어 프로세스의 격리 및 자원 관리를 향상시킵니다. 네임스페이스는 격리를 제공하고, Cgroup은 자원의 사용을 제한합니다. 이러한 조합은 효과적인 리소스 관리 및 격리된 환경을 제공하는 컨테이너 기술의 기반이 됩니다.
컨테이너는 가볍고, 이동이 쉬우며, 격리되고, 관리하기 편합니다.
컨테이너는 프로세스 입니다. 호스트 OS 내에서 앞서 보여드렸던, https 프로세스와 동일하다 보면 됩니다. 그러면 docker 에서 실행 중인 httpd 프로세스를 한번 확인해 보겠습니다.
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
927717d2d026 httpd "httpd-foreground" 4 seconds ago Up 3 seconds 80/tcp stupefied_gagarin
182ddd3df992 httpd "httpd-foreground" 5 seconds ago Up 4 seconds 80/tcp relaxed_lovelace
4d50ad075f73 httpd "httpd-foreground" 6 seconds ago Up 5 seconds 80/tcp upbeat_goldwasser
cfb8c7c071b0 httpd "httpd-foreground" 8 seconds ago Up 7 seconds 80/tcp crazy_chandrasekhar
4개의 컨테이너가 구동중이고, 각자 격리된 형태입니다. 자원만 충분하다면 컨테이너를 ulimit 에 설정된 openfile 이 받아주는 한계에서 굉장히 많은 컨테이너를 실행할수 있습니다. 컨테이너 네트워크또한 호스트와 분리한다면 더욱더 많은 컨테이너를 실행할수 있습니다.
이러한 컨테이너의 형태는 우리 엔지니어들이 입이 마르고 닳도록 말하는 kubernetes 와 연결되어있습니다.
N+1개로 이루어진 Pod는 Node에 스케줄링됩니다. 위에서 예제로 보인 4개의 컨테이너의 실행은 네번이나 run 커멘드를 실행해야 하므로 아주 귀찮습니다. Kubernetes 에서 100개의 컨테이너를 생성하는 방법은 아래와 같습니다.
이러한 형태로 선언만 하면 이제 끝입니다. 이런 방법으로 우리는 httpd Container를 쉽게 만들수 있습니다. 그럼 프로세스에 이어서 바로 쿠버네티스로 넘어왔는데, 뭔가 빠져있다 생각하지 않나요? 바로 노드입니다. 쿠버네티스는 컨테이너 오케스트레이션이라 불립니다. 연결된 Node에 API를 이용하여 애플리케이션과 서비스를 구성하고 관리하고 조정합니다.
드디어 오늘의 이야기의 핵심에 다가가고 있습니다.
쿠버네티스는 결국 리눅스에 설치됩니다.
우리는 Pod와 Service 오브젝트는 간단히 다룰수있지만 추상화의 너머에 있는 Kubernetes의 프로세스와 노드에서 돌고있는 Kubelet 에 대해선 간단히 다룰수 없습니다.
우리는 다양한 것들이 추상화되어있는 시대를 살고있습니다. 그래서 그 심연을 들여다 보면 멘탈이 날아가는 일이 비일비재 합니다. 이러한 일들에 내성을 가지고 이겨내기위해선 결국엔 기본능력이 오르는 수밖에 없습니다.
기본능력이라 함은 리눅스 입니다.
항상 리눅스를 잘하려면 어떻게 해야하나요? 라는 질문을 듣습니다. 리눅서로서 사실 죄송한 말이지만 리눅스를 잘하는 기준은 어디에도 없고 리눅스 서버운영에는 많은 명령어가 필요하지 않습니다. 대부분 10개이내의 명령어를 사용합니다. 하지만 대부분의 일은 그 명령어들 내에서 처리됩니다.
그렇다면 리눅스를 잘하려면 어떻게 해야하냐? 결국엔 다양한 명령어들을 경험하고 손에 익어서 문제가 발생한 시점에 그 명령어를 사용해서 시스템을 점검하는것이 리눅스를 잘하는 것입니다.
저 같은 경우엔 처음보는 시스템도 30분이면 대부분 파악이 됩니다.
그 힘은 다양한 리눅스 환경에서 헤멘탓이 큽니다. 디렉토리 구조 패키지형태 명령어 스타일 배포판 마다 조금씩 다릅니다. 이런경우 저는 레드헷 계열 리눅스를 편하게 쓰지만 처음 보는 리눅스라 해서 어려워하지 않습니다. 이유는 간단합니다.
시작하는 엔지니어라면 리눅스의 구조 동작을 먼저 공부하시고 그 다음엔 명령어 프로세스 동작 그리고 간단한 스크립트도 짜보는것을 추천합니다. 또한 리눅스에선 다양한 명령어 들이 있습니다. 지금 이순간에도 누군가가 리눅스의 명령어를 만들고 있을 것입니다. 자신만의 명령어를 만들어도 좋습니다. 리눅스에 익숙해지고 많이 두드려 보세요.
손가락에 익은 명령어는 시스템을 배신하지 않습니다.
사실 가끔 합니다 (rm -rf *) 과 같은..누구나 하는 실수입니다.(저는안했습니다.)
기승전리눅스를 이야기하게 되었네요.
하지만 리눅스는 현대의 IT를 이끌고있는 근간이고 대부분의 시스템이 리눅스에서 구동된다는 사실을 안다면 근본인 리눅스를 하지 않을수 없다 생각합니다.
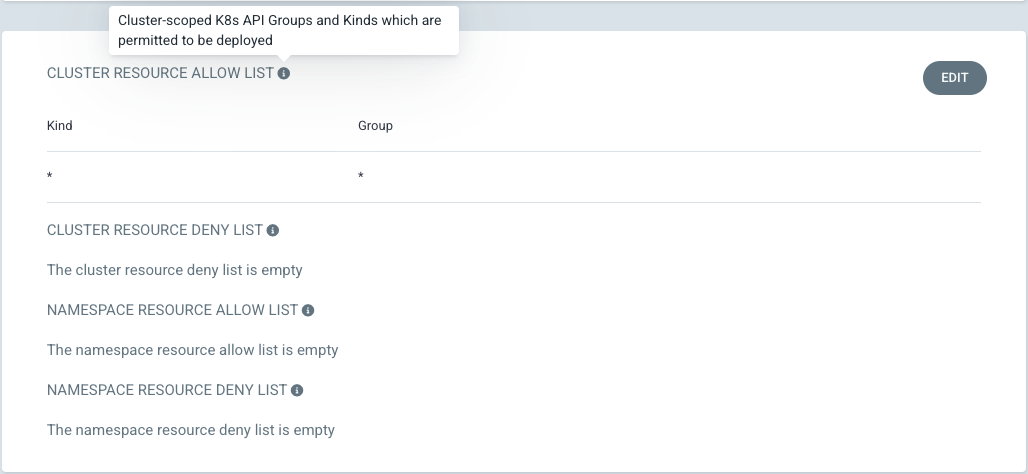
In some cases, Cluster RBAC does not work with ArgoCD.
Control cluster resources with "CLUSTER RESOURCE ALLOW LIST". When you create a new ArgoCD project, it has no permissions by default, so it can only operate within the namespace to NOT create cluster RBAC.