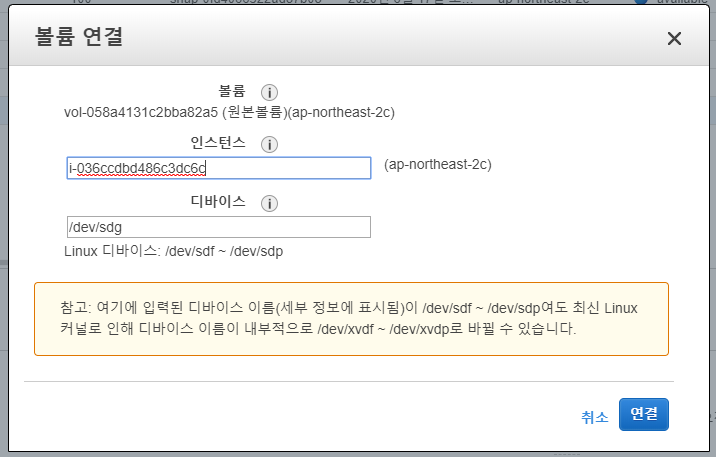
명령어로 UUID 생성해서 넣어줄수 있다. UUID 가 보인다면 new / org 변수에 UUID 를 export 해주자 UUID 는 사람마다 다들테니 각각 잘확인해서 복붙하자.
# export new=’3a26abfe-67eb-49e4-922a-73f6cd132402’ # export org=’781f875d-4262-4f01-ba72-d6bd123785f5’ # sed -i -e "s/$org/$new/g" etc/fstab # sed -i -e "s/$org/$new/g" boot/grub2/grub.cfg # mount -B /dev dev # mount -B /proc /proc # mount -B /sys sys # chroot .
위 명령어를 치면 /mnt/new 경로에서 지정한 UUID 로 fstab 안의 UUID를 변경하고 grub.cfg 안의 UUID 또한 자동으로 치환해줄거다. 그런다음 3개의 경로를 bind mount 하고 현재위치에서 chroot . 를 치면 chroot 가 현재위치로 변경된다.
[root@ip-172-31-12-119 mnt]# dd bs=16M if=/dev/xvdg1 of=/dev/xvdf1 count=113 113+0 records in 113+0 records out 1895825408 bytes (1.9 GB) copied, 29.3328 s, 64.6 MB/s [root@ip-172-31-12-119 mnt]# resize2fs -p /dev/xvdf1 resize2fs 1.43.5 (04-Aug-2017) Resizing the filesystem on /dev/xvdf1 to 1310464 (4k) blocks. The filesystem on /dev/xvdf1 is now 1310464 (4k) blocks long.
[root@ip-172-31-12-119 mnt]# resize2fs -p /dev/xvdf1 resize2fs 1.43.5 (04-Aug-2017) Resizing the filesystem on /dev/xvdf1 to 1310464 (4k) blocks. The filesystem on /dev/xvdf1 is now 1310464 (4k) blocks long.
#cd /mnt/new # mount -B /dev dev # mount -B /proc /proc # mount -B /sys sys # chroot .
제일 중요한 부분은 /proc 부분이다. mount bind 해주지 않으면 정상적으로 파티션 포지션을 불러오지 않는다.
chroot 까지 정상적으로 마쳐 지면 이제 거의 다왔다. 그냥은 안되고 몇가지를 수정해줘야 한다. 근래에 사용하는 aws 의 HOST가 변경되어서 볼륨 포지션이 좀 변경되었기 때문이다. amazon linux 1 에서는 /boot/grub/device.map의 수정이 필요하다. 하이퍼 바이저가 디바이스를 호출하는 이름이 변경된것이므로 수정하지 않으면 grub-install 이 불가능하다.
# grub-install /dev/xvdf Installation finished. No error reported. This is the contents of the device map /boot/grub/device.map. Check if this is correct or not. If any of the lines is incorrect, fix it and re-run the script `grub-install'. (hd0) /dev/xvda (hd1) /dev/xvdf (hd2) /dev/xvdg
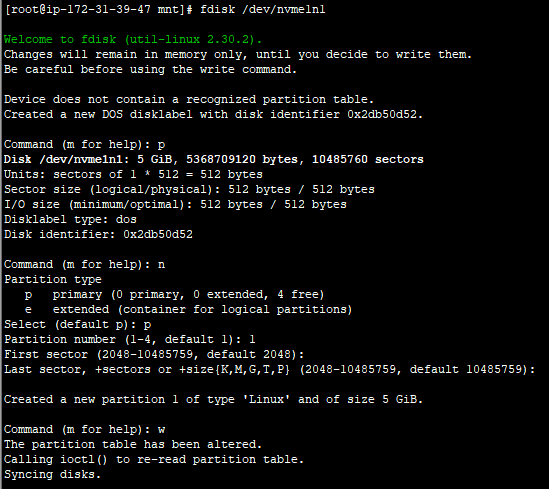
amazon linux 1 의 경우엔 파티션이 xvda 로 보여서 xvda 의 첫번째 파티션은 1번을 확장한다.
amazon linux 2 의 경우엔 파티션이 nvme1n1p1 으로 보이므로 실제 명령어는
# growpart /dev/nvme1n1 1
로 명령어를 쳐야 한다. growpart 로 파티션을 확장하면 Disk label type: dos -> Disk label type: gpt 변경되고,
위처럼 디스크 라벨 부터 파티션 타입까지 변경된다.
fdisk -l 명령어로 확인하며 진행하자.
이제 다음은 파일시스템의 확장이 필요하다. 파일시스템 확장은 resize2fs 명령어로 확장한다.
# resize2fs /dev/xvda1 resize2fs 1.43.5 (04-Aug-2017) Filesystem at /dev/xvda1 is mounted on /; on-line resizing required old_desc_blocks = 1, new_desc_blocks = 2 The filesystem on /dev/xvda1 is now 5242363 (4k) blocks long.
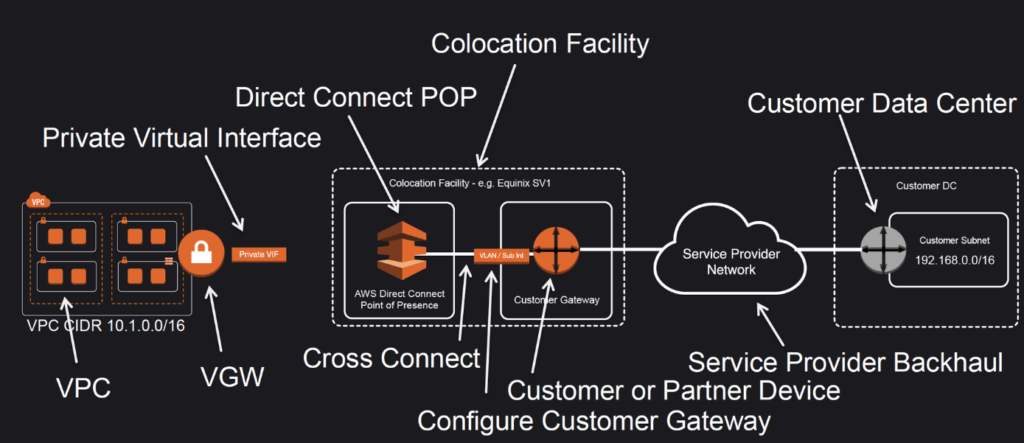
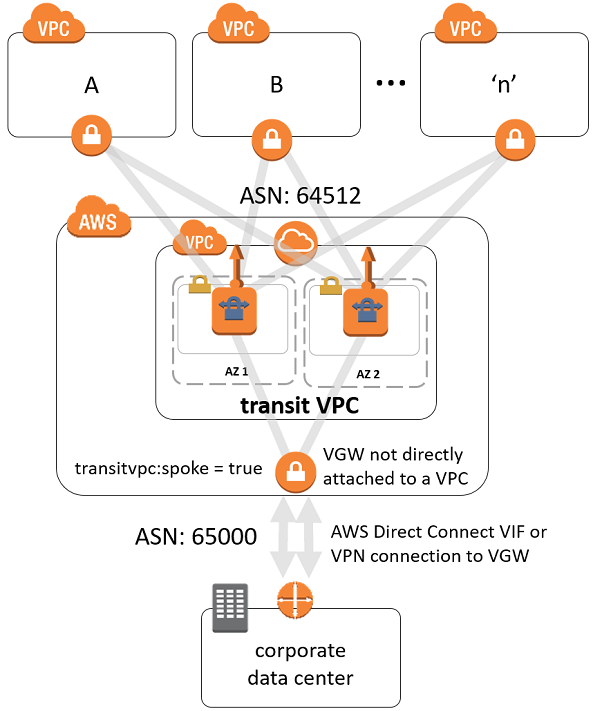
Amazon Virtual Private Cloud Connectivity Options - white paper 정말 도움이 많이되었다.
그렇게 많은것들을 보고나서 오늘 종로 솔데스크에서 시험을 봤다.
시험을 완료하자마자 성적표가 날아왔다.
총점: 80%
주제별 등급점수: 1.0 Design and implement hybrid IT network architectures at scale: 83% 2.0 Design and implement AWS networks: 85% 3.0 Automate AWS tasks: 100% 4.0 Configure network integration with application services: 71% 5.0 Design and implement for security and compliance: 83% 6.0 Manage, optimize, and troubleshoot the network: 57%
다음과 같이 성적표까지 바로 발송되었다. 아슬아슬 했다고 생각한다.
여담으로 AWS의 시험시스템이 변경되었다고 이전에 언급했는데 당일에 점수와 결과가 발송된다.