k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
karpenter-5bffc6f5d8-p2pxh 1/1 Running 0 9d 192.168.12.183 fargate-ip-192-168-12-183.ap-northeast-2.compute.internal <none> <none>
karpenter-5bffc6f5d8-qgcwn 1/1 Running 0 9d 192.168.13.157 fargate-ip-192-168-13-157.ap-northeast-2.compute.internal <none> <none>
Karpenter는 버전에 따라 Pod내에 Container 가 2개인 경우가 있다. 이경우엔 컨트롤러와 웹훅용도의 컨테이너가 두개가 동작한다. 일정버전 이상에서만 Fargate에 프로비저닝 된다. 그냥 v0.27.3버전 이상쓰자.
PodDisruptionBudget: PodDisruptionBudget은 클러스터의 안정성을 보장하기 위해 사용된다. 특정 서비스를 중단하지 않고 동시에 종료할 수 있는 Pod의 최대 수를 지정한다.
ServiceAccount: Karpenter가 동작하려면 해당 권한을 가진 Kubernetes의 ServiceAccount가 필요하다. ServiceAccount는 Kubernetes 리소스에 대한 API 접근 권한을 제공한다.
Secret-webhook-cert: Karpenter의 웹훅에 사용되는 TLS 인증서를 저장하는 Secret이다. 이를 통해 웹훅이 안전하게 통신할 수 있다.
ConfigMap-logging: Karpenter의 로깅 설정을 저장하는 ConfigMap이다. 로깅 수준, 출력 형식 등을 지정할 수 있다.
ConfigMap: Karpenter의 기본 설정을 저장하는 ConfigMap입니다. 예를 들어, 프로비저닝 로직과 관련된 설정을 저장할 수 있다.
RBAC-related components: Karpenter의 동작에 필요한 권한을 정의하는 역할(Role), 클러스터 역할(ClusterRole), 역할 바인딩(RoleBinding), 클러스터 역할 바인딩(ClusterRoleBinding) 등이 포함된다. 이러한 리소스들은 Karpenter가 Kubernetes API를 사용하여 필요한 작업을 수행할 수 있도록 한다.
Service: Karpenter 컨트롤러의 API를 노출하는 Kubernetes Service이다. 이를 통해 웹훅 및 기타 클라이언트가 Karpenter에 접속할 수 있다.
Deployment: Karpenter의 컨트롤러 구성 요소를 정의하는 Deployment이다. 컨트롤러는 Karpenter의 주요 기능을 실행하는 프로세스이다.
Webhooks: Karpenter는 웹훅을 사용하여 다양한 요청을 처리하고, 배포 전에 검증 또는 변형 작업을 수행한다. 이 웹훅을 설정하는 데 사용되는 리소스가 여기에 포함되어 있다.
이컴포넌트들은 helm 명령어로 karpenter의 template 을 outout 했을때 나온 manifast를 나열한것이다. 이 9가지의 컴포넌트 외에 두개의 CRD - CustomResourceDefinition - 가 있다.
provisioners.karpenter.sh CRD는 Karpenter가 새로운 노드를 프로비저닝할 때 사용하는 정책을 정의한다. 이 CRD는 클러스터의 노드를 동적으로 스케일링하기 위한 설정을 포함하며, 예를 들어 어떤 유형의 인스턴스를 사용할지, 어떤 가용 영역에서 노드를 프로비저닝할지, 최대 노드 수는 얼마인지 등의 정보를 포함할 수 있다. Provisioner 오브젝트는 Karpenter에게 필요한 리소스 요구사항을 알려주고, Karpenter는 이 정보를 사용하여 클러스터를 효과적으로 관리하고 노드를 프로비저닝한다. Provisioner는 공급 업체, 가용 영역, 인스턴스 유형, 노드 수량 등에 대한 세부 정보를 포함하여 워크로드 요구사항에 가장 적합한 노드를 선택하는 데 도움이 된다. Karpenter는 이러한 Provisioner 오브젝트를 감시하고, 워크로드의 요구사항에 따라 적절한 시기에 새 노드를 프로비저닝한다. 수동으로 노드를 추가하거나 제거할 필요가 없다.
awsnodetemplates.karpenter.k8s.aws CRD는 Karpenter가 AWS 클러스터에서 노드를 프로비저닝할 때 사용 한다. 이 CRD는 AWS에서 노드를 프로비저닝하는 데 필요한 세부 정보와 구성을 제공한다. 예를 들자면, 사용할 EC2 인스턴스 유형, 가용 영역, 보안 그룹, IAM 역할, 사용자 데이터, 노드 그룹 레이블 등의 정보가 포함될 수 있다. awsnodetemplates 를 사용하면 Karpenter가 AWS에서 노드를 프로비저닝하는 방법을 세밀하게 제어하고 구성할 수 있다. 이를 통해 클러스터의 노드가 클러스터의 워크로드 요구사항과 AWS의 특정 요구사항에 가장 잘 맞도록 조정할 수 있다.
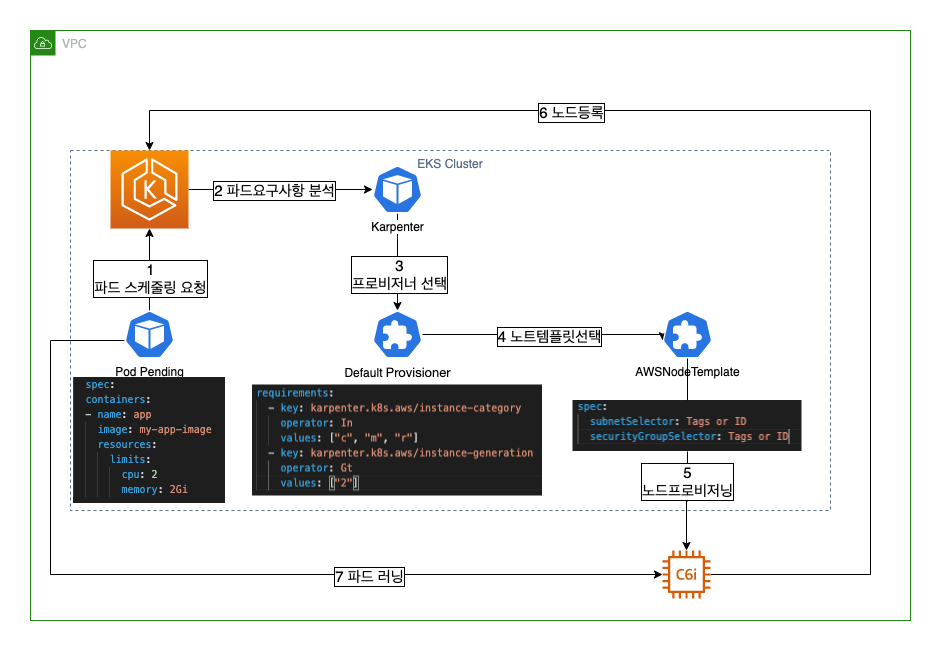
한번 그럼 다이어그램으로 그려 봤다.
파드 스케줄링 요청: 파드가 생성되면 쿠버네티스 스케줄러는 이를 적합한 노드에 스케줄링하려고 시도한다. 만약 충분한 리소스를 가진 노드가 없다면, 파드는 Pending 상태가 된다.
파드 요구사항 분석: Karpenter는 Pending 상태의 파드를 주기적으로 검사하여 각 파드의 요구사항을 분석한다. 요구사항에는 CPU, 메모리, GPU, EBS 등의 리소스 요구사항이 포함될 수 있다.
프로비저너 선택: Karpenter는 파드 요구사항에 가장 적합한 프로비저너를 선택한다. 프로비저너는 provisioners.karpenter.sh CRD에 의해 정의되며, 어떤 유형의 노드를 프로비저닝할지, 어떤 가용 영역에서 노드를 프로비저닝할지 등의 정책을 포함한다.
노드 템플릿 선택: 선택된 프로비저너는 적합한 노드 템플릿을 선택하거나 생성한다. 노드 템플릿은 awsnodetemplates.karpenter.k8s.aws와 같은 클라우드 공급자 특정 CRD에 의해 정의될 수 있으며, 사용할 EC2 인스턴스 유형, 보안 그룹, IAM 역할 등의 세부 정보를 포함할 수 있다.
노드 프로비저닝: 선택된 노드 템플릿에 기초하여 새 노드가 프로비저닝된다. 이 과정은 클라우드 공급자 API를 사용하여 수행한다.
노드 등록: 프로비저닝된 노드는 쿠버네티스 클러스터에 등록된다
파드 러닝: 스케줄러는 Pending 상태의 Pod를 노드에 스케줄링하여 노드는 Runing 상태로 변경된다.
다음과 같이 patch 를 하고 rollout restart 까지 하면 pod가 Fargate 로 생성된다.
k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aws-load-balancer-controller-76db948d9b-qzpsd 1/1 Running 0 46s 192.168.11.65 fargate-ip-192-168-11-65.ap-northeast-2.compute.internal <none> <none>
aws-load-balancer-controller-76db948d9b-t26qt 1/1 Running 0 88s 192.168.11.180 fargate-ip-192-168-11-180.ap-northeast-2.compute.internal <none> <none>
시간날때마다 Fargate 로 추가되어야 하는 에드온들을 Fargate 로 생성하는 방법을 작성하겠다.