일단 SQS를 터질때 까지 밀어넣어 보기로 했다.
목표 메시지수는 100만건.
100만건의 메시지를 100초안에 SQS에 넣는게 목표다. TPS 10000 이라는 소리다.
목표를 이루기위해선 첫번째 SQS의 TPS는 3000이다. 초당 3000의 메시지를 넣을수 있다.
먼저 큐를 4개를 만들었다. 목표수치에 가려면 TPS가 10000은 나와야한다.
그렇다면 큐를 병렬로 줄세운다 4개의 큐를 만든다.
이제 넣어봤다.
import boto3
import json
import uuid
from concurrent.futures import ThreadPoolExecutor
import random
import string
sqs = boto3.client('sqs')
queue_urls = [
'linuxer-sqs-1',
'linuxer-sqs-2',
'linuxer-sqs-3',
'linuxer-sqs-4'
]
def random_string(length):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def create_dummy_data():
return {
'id': str(uuid.uuid4()),
'data': f"host-{random_string(5)}-count",
'padding': random_string(10 * 1024 - 100) # 10KB 크기의 더미 데이터를 생성
}
def send_message_batch(queue_url, messages):
entries = []
for idx, message in enumerate(messages):
entries.append({
'Id': str(idx),
'MessageBody': json.dumps(message)
})
response = sqs.send_message_batch(
QueueUrl=queue_url,
Entries=entries
)
return response
def generate_and_send_dummy_data(num_messages=100000, batch_size=10, num_threads=10):
with ThreadPoolExecutor(max_workers=num_threads) as executor:
for _ in range(num_messages // (batch_size * num_threads * len(queue_urls))):
batch_futures = []
for queue_url in queue_urls:
messages = [create_dummy_data() for _ in range(batch_size)]
future = executor.submit(send_message_batch, queue_url, messages)
batch_futures.append(future)
for future in batch_futures:
future.result()
if __name__ == '__main__':
generate_and_send_dummy_data()
대충 이코드는 TPS 100 정도이다.
5분 정도 걸려서 10만 건의 메시지를 모두 PUT했다. 분당 20000 TPS 333정도다.
병렬처리했다.
import boto3
import json
import uuid
from concurrent.futures import ThreadPoolExecutor
from multiprocessing import Process
import random
import string
sqs = boto3.client('sqs')
queue_urls = [
'linuxer-sqs-1',
'linuxer-sqs-2',
'linuxer-sqs-3',
'linuxer-sqs-4'
]
def random_string(length):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def create_dummy_data():
return {
'id': str(uuid.uuid4()),
'data': f"host-{random_string(5)}-count",
'padding': random_string(10 * 1024 - 100) # 10KB 크기의 더미 데이터를 생성
}
def send_message_batch(queue_url, messages):
entries = []
for idx, message in enumerate(messages):
entries.append({
'Id': str(idx),
'MessageBody': json.dumps(message)
})
response = sqs.send_message_batch(
QueueUrl=queue_url,
Entries=entries
)
return response
def generate_and_send_dummy_data(queue_url, num_messages=1000000, batch_size=10, num_threads=10):
with ThreadPoolExecutor(max_workers=num_threads) as executor:
for _ in range(num_messages // (batch_size * num_threads)):
batch_futures = []
for _ in range(num_threads):
messages = [create_dummy_data() for _ in range(batch_size)]
future = executor.submit(send_message_batch, queue_url, messages)
batch_futures.append(future)
for future in batch_futures:
future.result()
def start_processes(num_processes):
processes = []
for queue_url in queue_urls:
for _ in range(num_processes):
process = Process(target=generate_and_send_dummy_data, args=(queue_url,))
processes.append(process)
process.start()
for process in processes:
process.join()
if __name__ == '__main__':
num_processes = 4
start_processes(num_processes)
501 17512 16975 0 9:27PM ttys001 0:00.21 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python main.py
501 17513 17512 0 9:27PM ttys001 0:00.05 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.resource_tracker import main;main(6)
501 17514 17512 0 9:27PM ttys001 0:14.41 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=9) --multiprocessing-fork
501 17515 17512 0 9:27PM ttys001 0:14.50 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=11) --multiprocessing-fork
501 17516 17512 0 9:27PM ttys001 0:14.36 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=14) --multiprocessing-fork
501 17517 17512 0 9:27PM ttys001 0:14.60 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=16) --multiprocessing-fork
501 17518 17512 0 9:27PM ttys001 0:14.55 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=18) --multiprocessing-fork
501 17519 17512 0 9:27PM ttys001 0:14.21 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=20) --multiprocessing-fork
501 17520 17512 0 9:27PM ttys001 0:14.16 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=22) --multiprocessing-fork
501 17521 17512 0 9:27PM ttys001 0:14.11 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=24) --multiprocessing-fork
501 17522 17512 0 9:27PM ttys001 0:14.46 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=27) --multiprocessing-fork
501 17523 17512 0 9:27PM ttys001 0:14.55 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=29) --multiprocessing-fork
501 17524 17512 0 9:27PM ttys001 0:14.24 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=31) --multiprocessing-fork
501 17525 17512 0 9:27PM ttys001 0:14.19 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=33) --multiprocessing-fork
501 17526 17512 0 9:27PM ttys001 0:14.28 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=35) --multiprocessing-fork
501 17527 17512 0 9:27PM ttys001 0:14.18 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=37) --multiprocessing-fork
501 17528 17512 0 9:27PM ttys001 0:14.49 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=39) --multiprocessing-fork
501 17529 17512 0 9:27PM ttys001 0:14.46 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=41) --multiprocessing-fork이제 멀티프로세스로 꼽는다!!
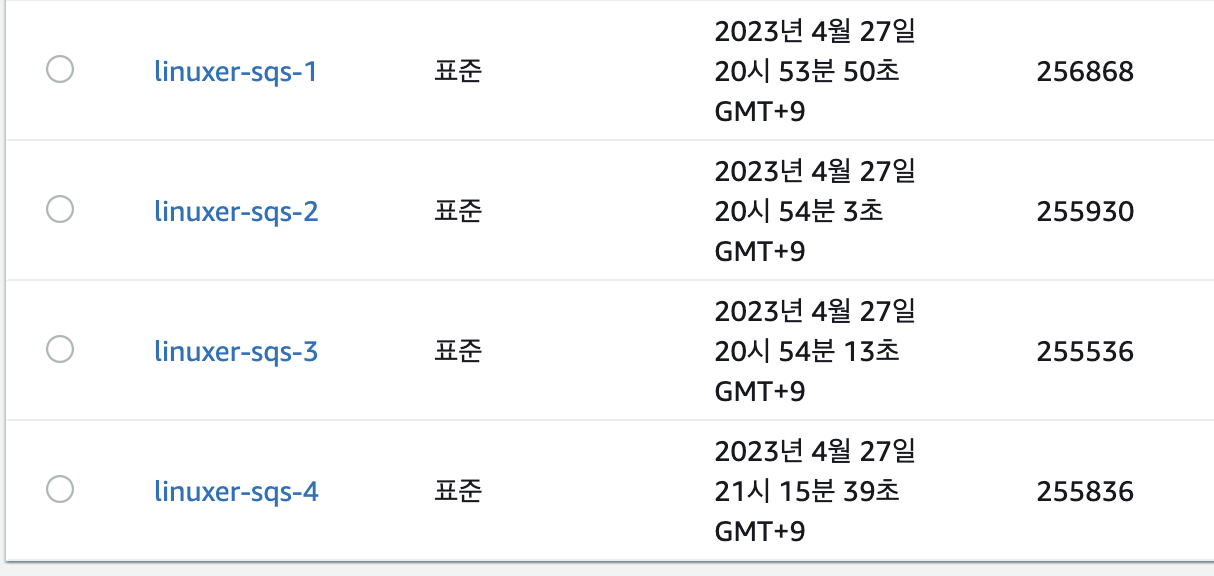
코드보니 400만개를 넣도록 되어있어서 100만개 넣을시점에 끊었다.
10분정도에 100만개의 메시지.. TPS 1600 정도다 아직 더 올릴수 있는 가망성이 보이지만 이건이제 컴퓨팅의 문제다.num_processes = 12 4배다! 일단 터트려 보자.
ps -ef | grep "multiprocessing.spawn" | wc -l
49
49개의 프로세스가 미친듯이 공격을 한다. M1 진짜 좋다.
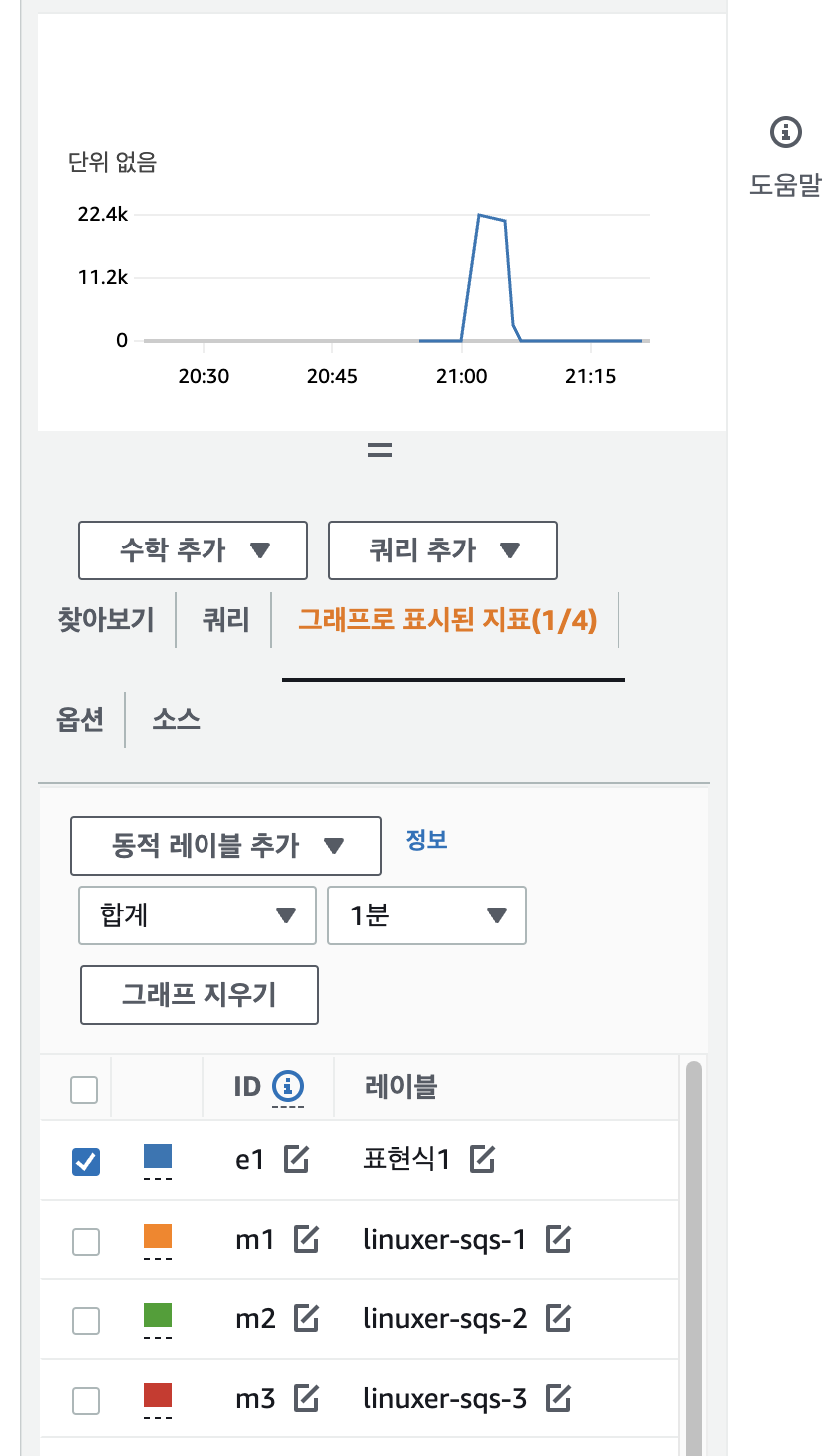
아...내 노트북으로 낼수있는 TPS는 1600이 한계다. 이제 컨슈밍을 할거다. SQS에 있는 데이터를 꺼내쓰는 속도를 확인할거다. 큐에는 100만개의 데이터가 쌓여있고 이걸 모두 소모하는 속도를 확인하려한다.
import boto3
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from multiprocessing import Process
sqs = boto3.client('sqs')
queue_urls = [
'linuxer-sqs-1',
'linuxer-sqs-2',
'linuxer-sqs-3',
'linuxer-sqs-4'
]
def receive_and_delete_message(queue_url, wait_time=20):
while True:
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=['All'],
MaxNumberOfMessages=1,
WaitTimeSeconds=wait_time
)
if 'Messages' in response:
message = response['Messages'][0]
receipt_handle = message['ReceiptHandle']
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=receipt_handle
)
else:
break
def process_messages(queue_url, num_threads=10):
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = [executor.submit(receive_and_delete_message, queue_url) for _ in range(num_threads)]
for future in as_completed(futures):
future.result()
def start_processes(num_processes):
processes = []
for queue_url in queue_urls:
for _ in range(num_processes):
process = Process(target=process_messages, args=(queue_url,))
processes.append(process)
process.start()
for process in processes:
process.join()
if __name__ == '__main__':
num_processes = 100
start_time = time.time()
start_processes(num_processes)
end_time = time.time()
print(f"Elapsed time: {end_time - start_time:.2f} seconds")
멀티프로세스 100개를 돌렸더니 M1이 뻣었다. 그렇지만 1분에 10만개 정도는 가볍게 뽑아가는걸 확인할수있었다.
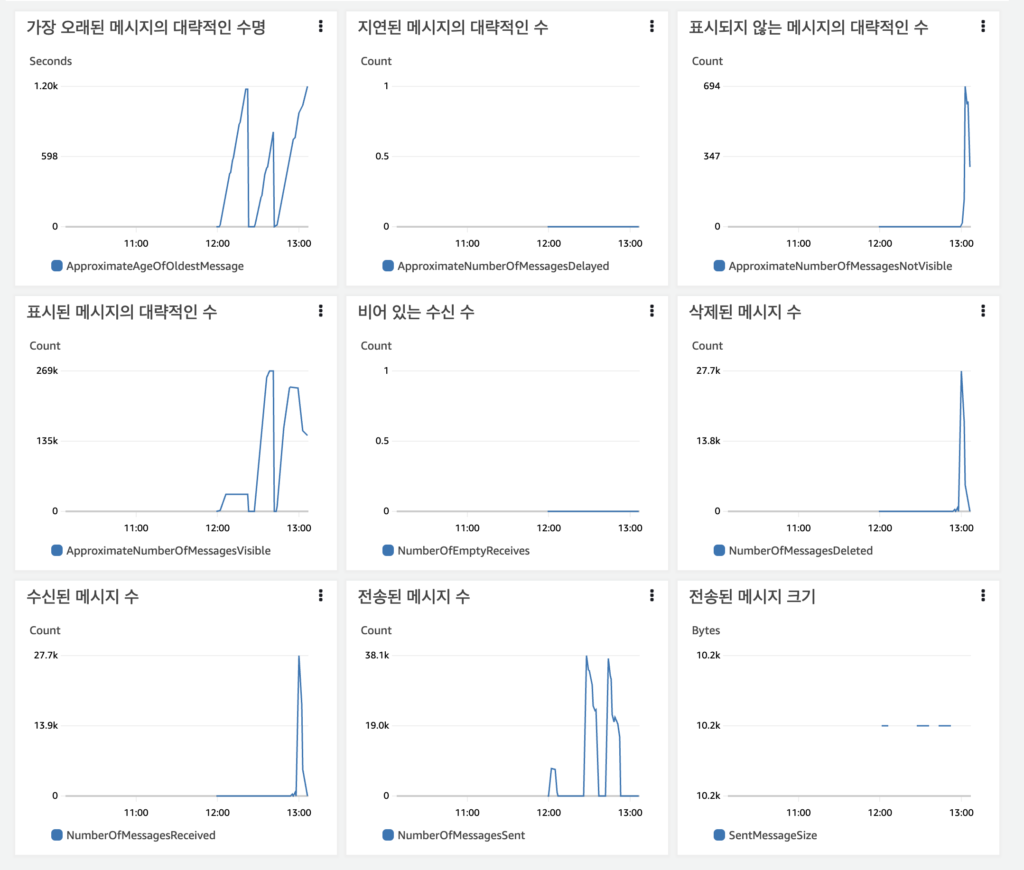
이 결과만으로 SQS는 튼튼한 큐라는걸 알수 있었다. 그럼 이렇게 하드코어하게 넣었으니 에러레이트를 확인해 봐야했다.
지연되거나 데드레터큐에 쌓인메시지는 없었다. 모두 정상적으로 소진된것이다.
여기서 결론은 mac book M1 air 로서 낼수 있는 퍼포먼스는 TPS1600이다. 분당 10만건의 메시지를 처리할수 있는 능력이라는것.. 이다음은 컴퓨팅 자원을 마음껏 넣어서 큐를 터트려 보겠다.
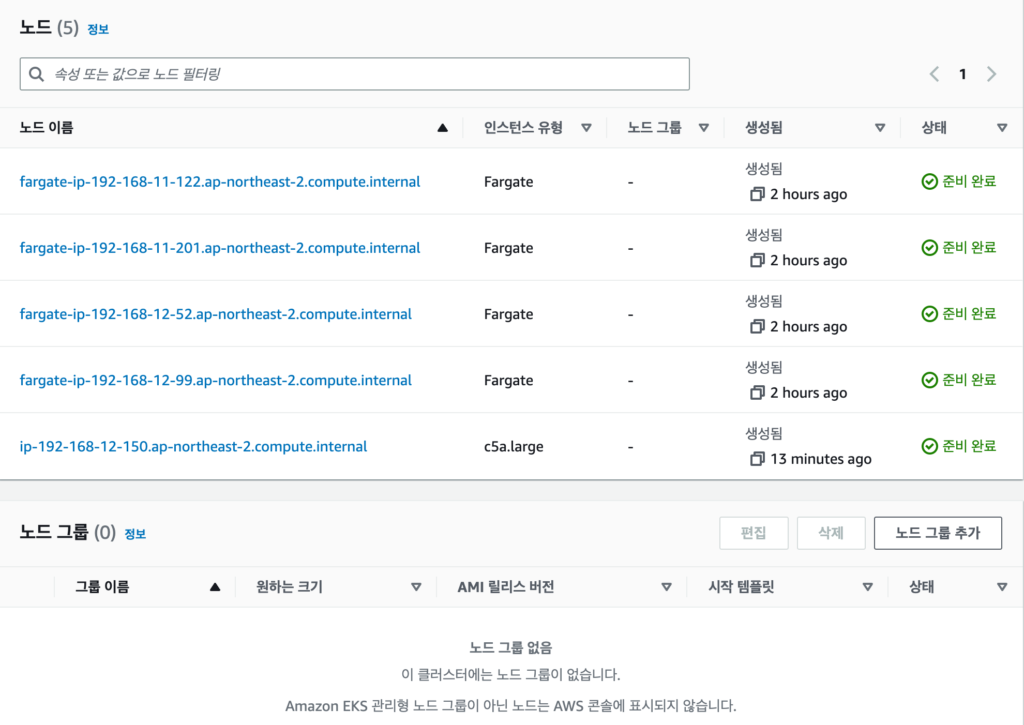
밤새 머리속에서 어떻게 하면 좋을까 고민하다가 EKS에서 Job을 이용해 병렬 처리속도를 늘려보기로 했다.
도커로 말고~
CMD로 job을 실행할때 파일을 지정해서 실행하도록 했다.
# Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY send.py receive.py ./
CMD ["python", "receive.py"]apiVersion: batch/v1
kind: Job
metadata:
name: sqs-test
spec:
parallelism: 20
template:
spec:
containers:
- name: sqs-test
image: sqs_test:latest
command: ["python3", "send.py"] // ["python", "receive.py"] 로 변경할수 있다.
resources:
limits:
cpu: "2"
memory: "2Gi"
requests:
cpu: "1500m"
memory: "1Gi"
restartPolicy: Never
backoffLimit: 4컨테이너 말고 parallelism 으로 20의 pod를 예약했다.
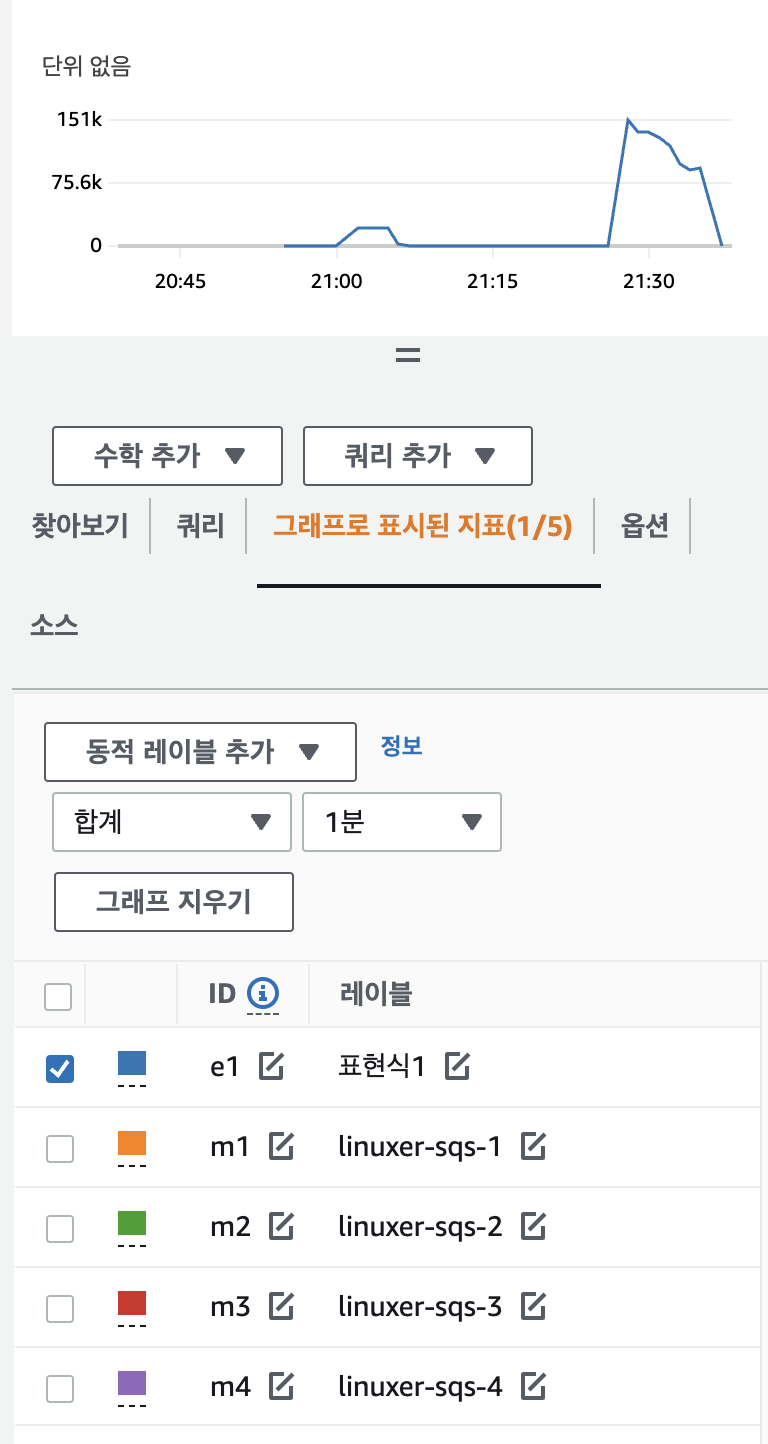
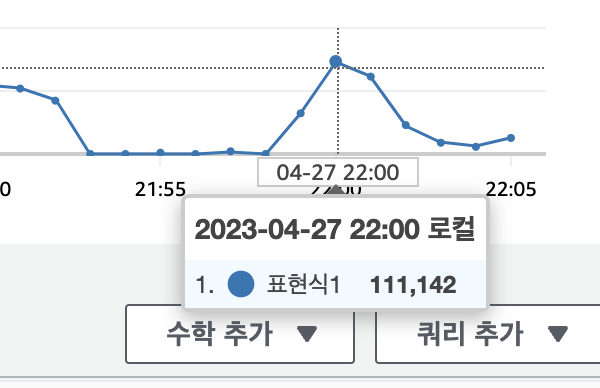
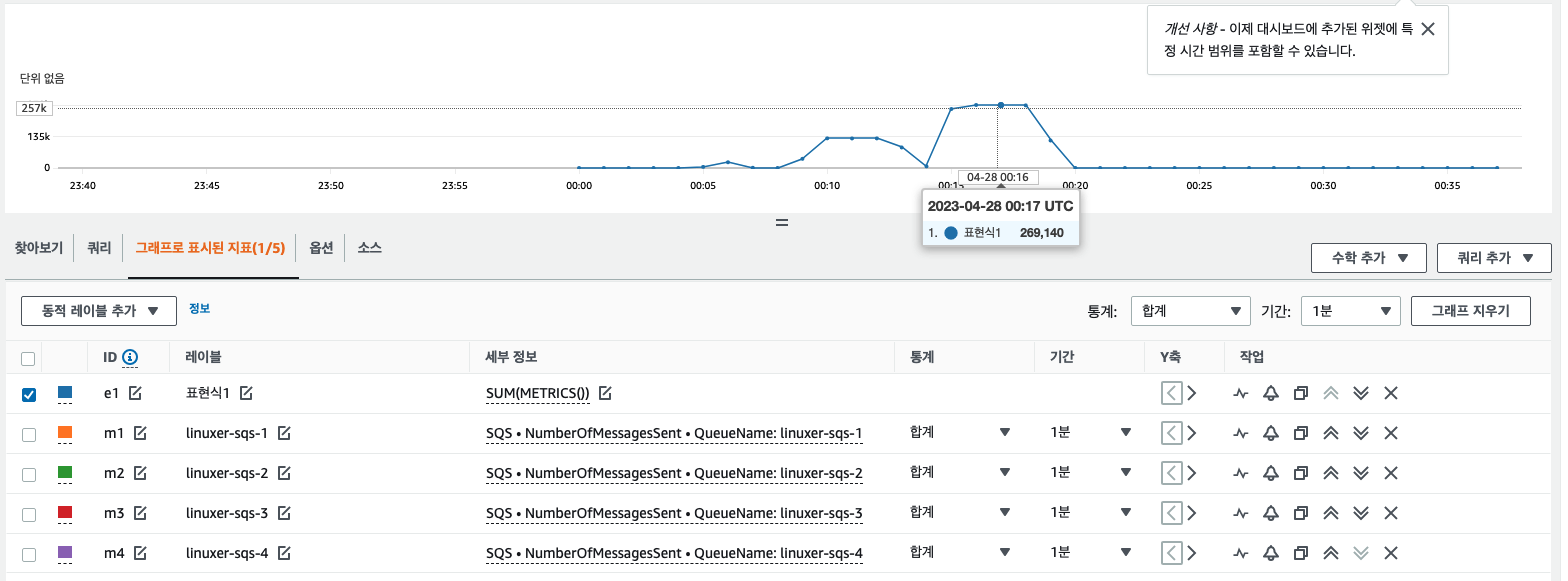
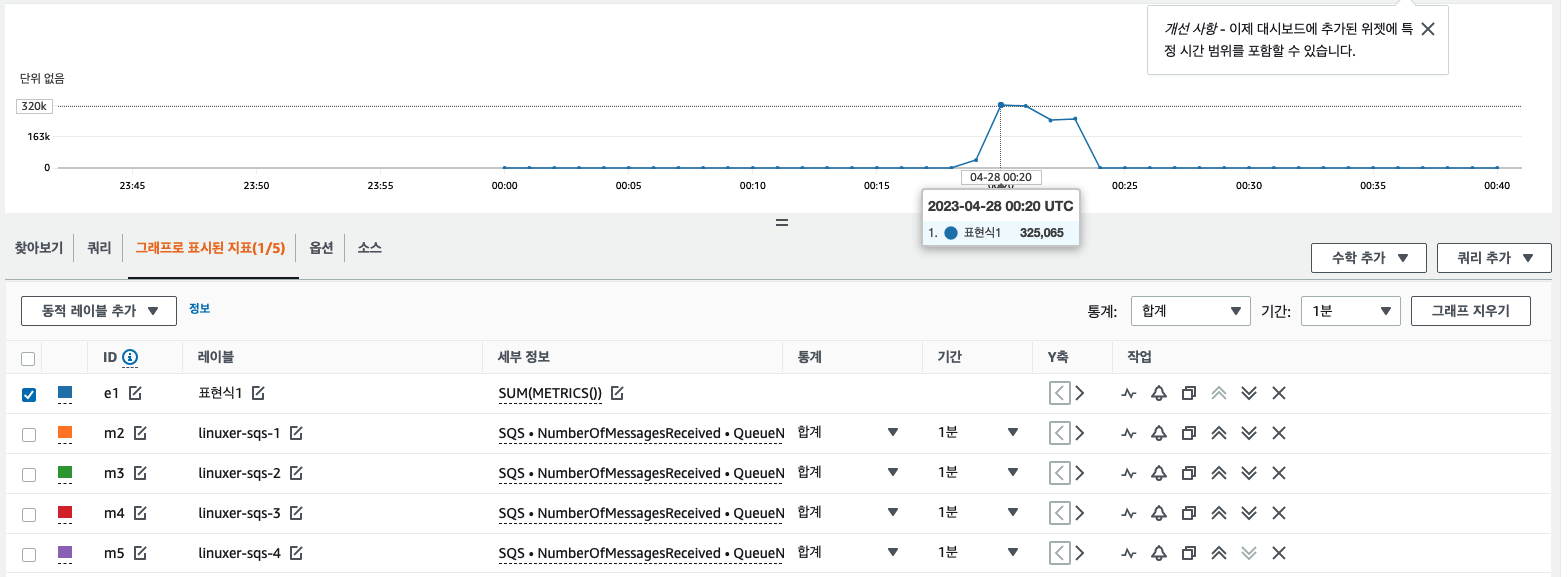
Send 는 분당 26만개 TPS 대략 4300
receive 는 32만개 대략 TPS 5000 정도이다.
5분에 100만개를 처리할수 있는 능력이라 보이고 이 플로우의 장점은 job에서 모든 데이터를 다꺼내쓰면 Completed로 컨테이너가 완료되므로 시간에 따른 큐에 대한 스케줄링이 가능하다는 뜻이다.
job을 스케줄링할때 큐에 쌓인 지연시간+큐에쌓인 갯수를 모니터링하고 job을 이용해 큐를 비우는 방식의 아키텍처를 설계할수 있다는 이야기다.
k get pod
NAME READY STATUS RESTARTS AGE
sqs-test-send-2s6h4 0/1 Completed 0 4m23s
sqs-test-send-5276z 0/1 Completed 0 4m23s
sqs-test-send-72ndr 0/1 Completed 0 4m22s
sqs-test-send-c24kn 0/1 Completed 0 4m22s
sqs-test-send-ccz5r 0/1 Completed 0 4m23s
sqs-test-send-fjfnk 0/1 Completed 0 4m23s
sqs-test-send-h2jhv 0/1 Completed 0 4m22s
sqs-test-send-k7b8q 0/1 Completed 0 4m22s
sqs-test-send-ljbv5 0/1 Completed 0 4m23s
sqs-test-send-mjvh9 0/1 Completed 0 4m23s
sqs-test-send-n8wh4 0/1 Completed 0 4m23s
sqs-test-send-ngskk 0/1 Completed 0 4m22s
sqs-test-send-qj9ks 0/1 Completed 0 4m22s
sqs-test-send-r87hf 0/1 Completed 0 4m22s
sqs-test-send-rr58h 0/1 Completed 0 4m23s
sqs-test-send-sf2bd 0/1 Completed 0 4m23s
sqs-test-send-svn8d 0/1 Completed 0 4m22s
sqs-test-send-tqfg4 0/1 Completed 0 4m23s
sqs-test-send-tv68j 0/1 Completed 0 4m22s
sqs-test-send-w99hx 0/1 Completed 0 4m23s결과가 놀라운데 4분23초 만에 pod의 스케줄링+job(120만건의 메시징컨슘)이 모두 완료된건이다.
이아키텍처에는 카펜터가 사용되었는데, 카펜터의 노드는 0에서 시작하여 새로 노드를 프로비저닝해서 깔끔하게 모두 완료된것이다. 스케줄링이 놀랍다.
재미있는 테스트였다.
이다음은 KaFka를 테스트 하겠다.