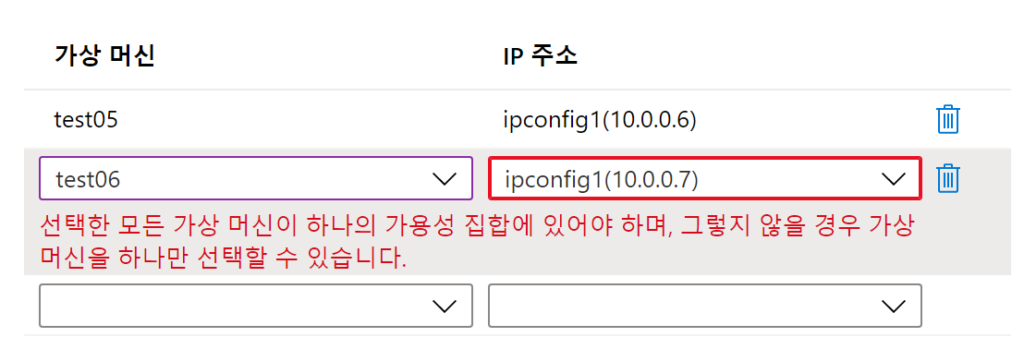
얼마전부터 route53 에서 cf 관련 느린이슈가 발생했다.
skt lte 망에서 발생하는 이슈인지 아니면 다른 이슈가 있는지 애매한 느낌이 있었다.
나도 ipv6 를 꺼서 지연문제가 해결될거라 생각했는데 조금 이상한 부분이 있어서 글을쓰게되었다.
먼저 route53의 응답이 이상하다.
linuxer.name 의 ns 레코드는
>linuxer.name
서버: [205.251.196.29]
Address: 205.251.196.29
linuxer.name nameserver = ns-1053.awsdns-03.org
linuxer.name nameserver = ns-1958.awsdns-52.co.uk
linuxer.name nameserver = ns-406.awsdns-50.com
linuxer.name nameserver = ns-544.awsdns-04.net
총 4개의 ns 를 가지고있다. 이 ns를 지정해보기로 한다.
>server ns-544.awsdns-04.net
기본 서버: ns-544.awsdns-04.net
Addresses: 2600:9000:5302:2000::1
205.251.194.32
서버를 ns-544.awsdns-04.net로 지정하면 ipv6 와 ipv4를 응답한다.
그 후에 다시 내도메인을 쿼리한다.
>linuxer.name
서버: ns-544.awsdns-04.net
Addresses: 2600:9000:5302:2000::1
205.251.194.32
*** ns-544.awsdns-04.net이(가) linuxer.name을(를) 찾을 수 없습니다. No response from server
그냥 도메인에 대한 응답인데..응답하지 않는다.
그럼 ns-544.awsdns-04.net 도메인의 서버IP인 205.251.194.32 로 쿼리를 날려본다.
>server 205.251.194.32
기본 서버: [205.251.194.32]
Address: 205.251.194.32
>linuxer.name
서버: [205.251.194.32]
Address: 205.251.194.32
linuxer.name internet address = 52.85.231.111
linuxer.name internet address = 52.85.231.10
linuxer.name internet address = 52.85.231.68
linuxer.name internet address = 52.85.231.42
linuxer.name nameserver = ns-1053.awsdns-03.org
linuxer.name nameserver = ns-1958.awsdns-52.co.uk
linuxer.name nameserver = ns-406.awsdns-50.com
linuxer.name nameserver = ns-544.awsdns-04.net
linuxer.name
primary name server = ns-1053.awsdns-03.org
responsible mail addr = awsdns-hostmaster.amazon.com
serial = 1
refresh = 7200 (2 hours)
retry = 900 (15 mins)
expire = 1209600 (14 days)
default TTL = 86400 (1 day)
linuxer.name name = 13.209.129.220
linuxer.name MX preference = 10, mail exchanger = mail.linuxer.name
linuxer.name ??? unknown type 257 ???
정리하자면 ipv4인 IP로 연결하면 응답하고 ipv6/ipv4로 응답하는 DNS로는 도메인에 대한 응답을 하지않는다...
이게 cf문제는 아니고 route53에서 ipv6 에 대한 응답을 정상적으로 못해서 발생하는 증상이 아닐까...하고 생각해본다..
다른의견이 있으시면 고견을 들려주시기 바란다.
https://www.facebook.com/groups/awskrug/permalink/2278291878939490/
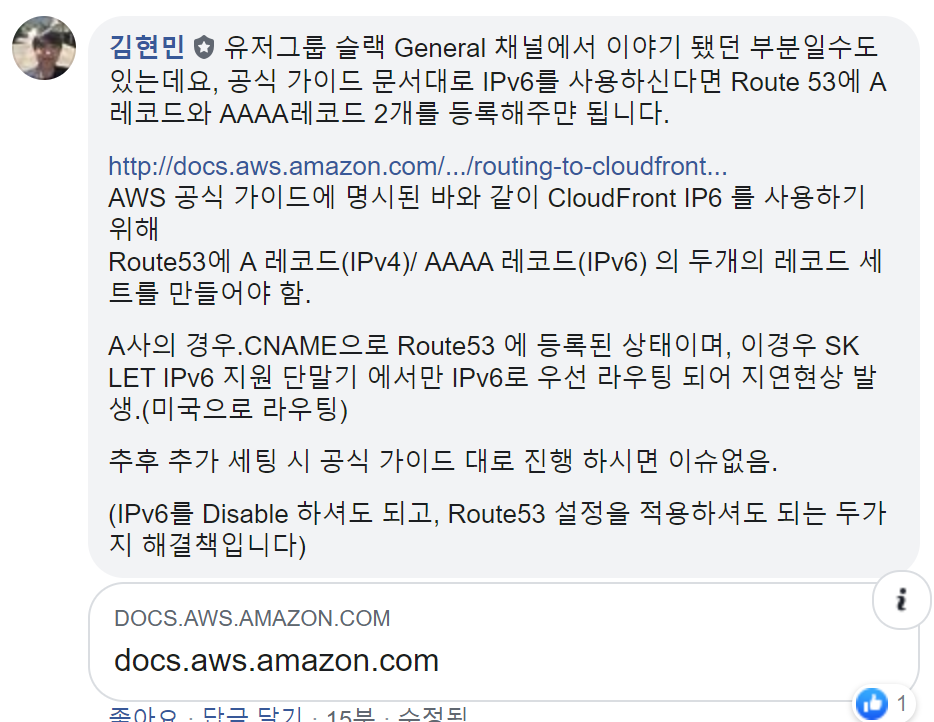
추가 댓글도 있으니 참고하시기 바란다.
2020/01/28 추가
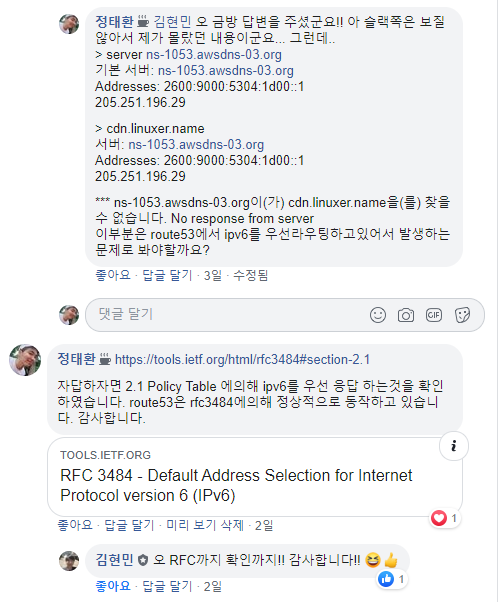
rfs3484에 의해 route53은 정상적인 응답을 하는것으로 보인다.
발생한 문제는 SK LTE 망내의 DNS에서 ipv6를 사용하므로서 정상적으로 라우팅하지 못한 문제로 보인다.
추가적인 내용은 다음포스팅에서 진행하겠다.