아웃바운드로 연결되는 모든 포트를 확인하기위해 flowlog 를 이용해야 했다.
먼저 흐름을 그려보자.
VPCflowlog enable -> cloudwatch loggroup -> lambda -> kinesis -> s3
이게 일단 저장하는 프로세스다.
지금은 좀더 간소화된 과정이 있으나 먼저 이전에 나온 방법을 학습하기 위해 이방법을 택했다.
먼저 저장 프로세스를 만들어보자.
https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/flow-logs.html
VPCflowlog 는 이런식으로 생성했다.
여기서 중요한것은 대상 로그 그룹이다. 역할은 자동생성 눌러서 그냥 만들어주자.
로그그룹은 따로 쌓기 위해서 새로만들어줬다.
로그그룹을 만들었다면 lambda를 생성하자. 람다는 어려울게 없다.
역할만 잘만들어주면 끝이다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:::" }, { "Effect": "Allow", "Action": [ "firehose:PutRecordBatch" ], "Resource": [ "arn:aws:firehose::*:deliverystream/VPCFlowLogsDefaultToS3"
]
}
]
}
따로 역할을 생성할때 람다를 선택하거나 역할을 만들고 신뢰관계를 추가하자.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
람다를 생성하고 위의 역할을 생성해서 부여해 주자. python 2.7 을 사용했다.
아래 소스를 인라인에 붙여 넣자.

환경변수또한 잘 생성해 줘야 한다.
람다의 제한시간을 1분으로 해주자.

람다에서는 템플릿 변경할게없다.
람다를 정상적으로 생성했다면 CloudWatch Loggroup 에서 lamdba 에대해서 설정해 줄게 있다.

Create Lambda subscription filter 설정이다.

생성한 Lambda 로 지정해주면 된다.
그다음은 kinesis다.

kinesis 에서도 Kinesis Data Firehose delivery streams 를 설정해야 한다.
VPCFlowLogsDefaultToS3 이름은 람다에서 설정한 환경에 넣은 이름으로 한다.
설정해줄 부분은

역할 자동 생성.

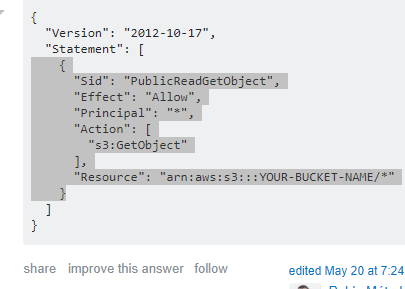
S3 버킷 지정이랑 compession 을 gzip 으로 변경하자. 거의 다왔다. 여기까지 했으면 이제 ETL 설정은 끝이다.
Athena 서비스로 이동하자
Athena 에서 테이블을 생성해야 한다.
CREATE EXTERNAL TABLE IF NOT EXISTS vpc_flow_logs (
Version INT,
Account STRING,
InterfaceId STRING,
SourceAddress STRING,
DestinationAddress STRING,
SourcePort INT,
DestinationPort INT,
Protocol INT,
Packets INT,
Bytes INT,
StartTime INT,
EndTime INT,
Action STRING,
LogStatus STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^([^ ]+)\s+([0-9]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([0-9]+)\s+([0-9]+)\s+([^ ]+)\s+([^ ]+)$")
LOCATION 's3:///';
지금까지의 과정이 정상적으로 진행됬다면 이쿼리가 잘실행된이후에 테이블이 생성된다.

그리고 이제 포트를 확인하자 사용한 쿼리다.
SELECT sourceport, count(*) cnt
FROM vpc_flow_logs
WHERE sourceaddress LIKE '10.0%'
GROUP BY sourceport
ORDER BY cnt desc
LIMIT 10;


이런 내용이 나오고..
이렇게 VPC 에서 사용하는 sourceport 를 확인할 수 있다.
정리하자면 VPC IP가 sourceaddress 인경우에 port 를 count 한다 이다.
읽어주셔서 감사하다 !