NCP 에선 centos8을 지원하지 않는다. 그런데 yum update 를 해서 커널이 변경되면 정상적으로 부팅되지 않는다.


이런 내용들이 인스턴스를 생성할때 안내된다.
그런데, 어제 퇴근후 Meetup과정에서 KR-2 zone은 yum update 가 가능하다는 내용을 전달 받았다. 어쩐지 가끔 yum update 해도 정상적으로 부팅되는 인스턴스가 있더라니..
퇴근길 Meetup - 퇴근길 Tech Meetup 서버 관리 자동화 자료이다.
여기에서 이상함을 느끼고 여쭤봤더니 KR-2에서 하라고 하셨다..그래서 오늘작업의 힌트를 얻었다...
최신의 OS 를 사용하고 싶은건 엔지니어의 본능이 아닌가? 그래서 테스트를 시작했다.
준비물은 다음과 같다.

서버이미지 centos 7.3으로 생성된 인스턴스 한대다.
ACG-포트포워딩-root password 확인 이런 부분은 서버생성 가이드를 참고하자.
https://docs.ncloud.com/ko/compute/compute-1-1-v2.html
인스턴스를 생성하고 인스턴스에 접속하자 마자 할일은 yum update 이다.
yum update -y
업데이트를 마무리하면 epel repo를 설치해 사용할 수 있다.
yum install epel-release -y
epel을 설치하는 이유는 dnf 를 사용하기 위함이다. yum->dnf 로 패키지 설치 방법을 변경할거다.
yum install -y yum-utils rpmconf
rpmconf -a
rpmconf -a 를 입력하면 패키지의 conf를 업데이트 할지를 물어본다.
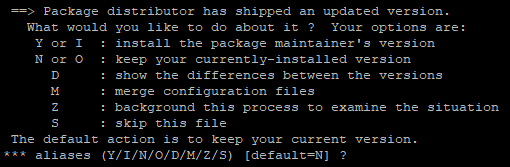
/etc/sysctl.conf
/etc/profile
/etc/shells
/etc/login.defs
/etc/nsswitch.conf
다섯개의 파일에 대해서 물어보는데 나는 모두 새로 인스톨하는것을 택했다. centos8 로 갈꺼니까.
package-cleanup --leaves
package-cleanup --orphans
다음은 패키지를 cleanup 하고, epel 을 설치한 이유인 dnf 를 설치한다.
yum install dnf -y
dnf 는 centos8 부터 기본적용된 rpm 패키지 관리 패키지인데 yum 에서 dnf로 변경됬다.
dnf 를 설치했다면 yum 을 지우자.
dnf -y remove yum yum-metadata-parser
rm -Rf /etc/yum
yum 을 지우고,
dnf install -y http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/centos-repos-8.2-2.2004.0.1.el8.x86_64.rpm http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/centos-release-8.2-2.2004.0.1.el8.x86_64.rpm http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/centos-gpg-keys-8.2-2.2004.0.1.el8.noarch.rpm
이제 centos8의 repo를 설치한다.
dnf -y upgrade https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
epel7 을 epel8로 업데이트 한다. 이제 centos8 패키지를 다운받을 수 있다.
dnf clean all
dnf 캐시를 clean 한다.
rpm -e `rpm -q kernel`
rpm -e --nodeps sysvinit-tools
rpm 명령어로 커널을 지운다. 여기서 모든 패키지가 삭제되지 않기때문에 후처리가 좀 필요하다.
dnf remove kernel-devel-3.10.0-1127.13.1.el7.x86_64 kernel-devel-3.10.0-327.22.2.el7.x86_64 kernel-devel-3.10.0-514.2.2.el7.x86_64 redhat-rpm-config iprutils-2.4.17.1-3.el7_7.x86_64 sysvinit-tools-2.88-14.dsf.el7.x86_64 sysvinit-tools-2.88-14.dsf.el7.x86_64 python36-rpmconf-1.0.22-1.el7.noarch
후에 의존성이 걸릴 패키지를 미리 삭제한다. 이 경우 NCP centos7.3 인스턴스에 맞춰서 의존성 패키지를 삭제한것이다. 의존성 문제가 발생하면 더삭제 해줘야 한다. 부담감 느끼지 말고 막 날리자. 안되면 처음부터 다시하면 된다.
dnf -y --releasever=8 --allowerasing --setopt=deltarpm=false distro-sync
명령어로 centos8 패키지를 설치한다. 새로 설치되는 패키지들을 유심히 보면 el8.x86_64 로 끝난다 centos8 사용하는 패키지 명으로 RHEL8 이라는 뜻이다. centos8 패키지가 잘설치된다는 소리다.
Complete!
이 단어가 보이면 거의 다된거다.
dnf -y install kernel-core
dnf -y groupupdate "Core" "Minimal Install"
dnf groupupdate 로 Core 와 Minimal Install 까지 업데이트 해주면 이제 된거다.
[root@s17308f26023 ~]# uname -a
Linux s17308f26023 3.10.0-514.2.2.el7.x86_64 #1 SMP Tue Dec 6 23:06:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
[root@s17308f26023 ~]# cat /etc/redhat-release
CentOS Linux release 8.2.2004 (Core)
리부팅을 아직 안해서 릴리즈는 올라갔으나, 커널버전은 centos7 이다. 이제 리부팅 해주자.
[root@s17308f26023 ~]# date
Wed Jul 1 15:50:15 KST 2020
[root@s17308f26023 ~]# cat /etc/redhat-release
CentOS Linux release 8.2.2004 (Core)
[root@s17308f26023 ~]# uname -a
Linux s17308f26023 4.18.0-193.6.3.el8_2.x86_64 #1 SMP Wed Jun 10 11:09:32 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
이제 NCP에서 Centos8을 올렸다!
차후 커널지원이나 업데이트에 따라서 OS가 정상작동하지 않을수 있다. 모니터링이 문제가 될거라 생각했는데 잘돈다...
Centos8을 NCP에서 사용하고 싶다면 한번 진행해 보시기 바란다.
읽어 주셔서 감사하다!