yum install bash-completion -y source <(kubectl completion bash) echo "source <(kubectl completion bash)" >> ~/.bashrc kubectl apply -f 파일명 kubectl apply -k ./경로 kubectl create -f 파일 kubectl get node kubectl get pods kubectl get pods --all-namespaces kubectl get service kubectl get events kubectl get pv kubectl get pvc kubectl get pc kubectl delete -f 파일명 kubectl delete -k 파일명
k8s-Centos7-install
#!/bin/sh setenforce 0 sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux swapoff -a modprobe br_netfilter echo '1' > /proc/sys/net/bridge/bridge-nf-call-iptables yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo yum install -y docker-ce cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOF yum install -y kubelet kubeadm kubectl systemctl enable docker systemctl enable kubelet sed -i 's/cgroup-driver=systemd/cgroup-driver=cgroupfs/g' /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
K8s centos7 base install
userdate 등에 넣고 쓸수있다.
#Master 에서 작업
kubeadm init --pod-network-cidr=사용하려는 pod cidr
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeadm join token 이 나오면 cluster node 에서 join 해준다

AWS-CloudFront-custom-header-ALB-filter
https://www.notion.so/CloudFront-ALB-f0086dec48b64f0883e0c6de5fd9da4c
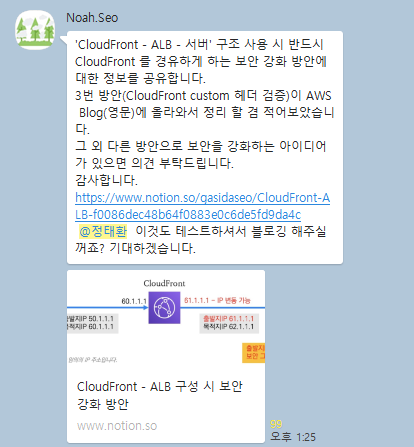
Noah.Seo 님의 이야기를 받아서 다른방법을 테스트하게 되었다.
4번째 방법이 번득 떠오른탓.
그럼 내가 생각하는 부분은 이렇다.
CloudFront -> ALB
끝...3번 방법은 WAF에서 X-Origin-Verify Custom Header 를 필터링 한다. ALB에서도 비슷한 기능이 있는바. 나는 이전부터 ALB에서 내 블로그 도메인이 아닌 ALB 도메인이나 IP로 접근하는것을 제한한 바가 있다.
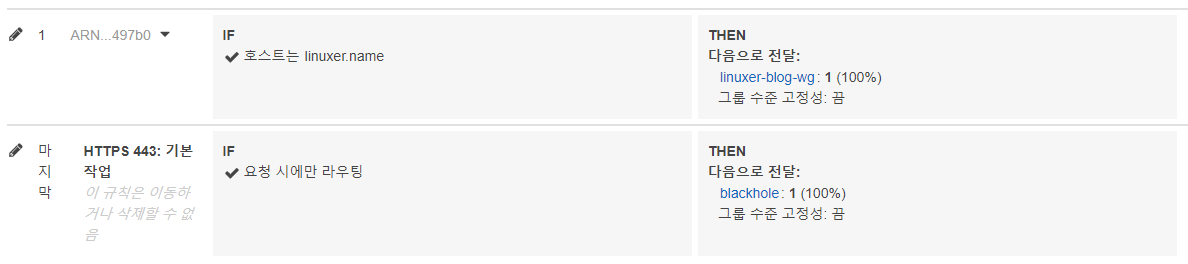
이 규칙이 바로 그것이다. Host 조건에 따라 Host가 다르면 아무 대상이 없는 blackhole 로 전달하게 된다. 그렇다. Custom Header를 ALB에서 필터링 할거다.
CloudFront 에서 Origin 을 수정한다.
단점은 ALB의 부하가 올라간다는것. 규칙에 의해 LCU 사용량이 증가할수 있다는 점이다.
그럼 셋팅해 보자.

X-Origin-Verify 헤더 네임을 추가하고 Value 로 test를 추가한다.

그리고 ALB의 규칙을 추가한다. 도메인 기반하여 http 헤더가 일치하면 라우팅. 그렇지않으면 두번째 규칙에 의해 blackhole로 전달한다. 지금 현재 정상적으로 헤더가 일치하여 사이트가 뜨는 상태다.
로 접근해보면 503에러가 발생하는것을 볼수있다.
재미있는 테스트 거리를 주신 Noah.Seo 님께 감사를 드린다.
Amazon CloudFront Origin Shield-Review
Origin Shield 가 출시 되었다.
Origin 에 전달되는 리퀘스트의 횟수를 줄여 관리비용을 줄인다고 한다.
먼저 캐싱율을 보자.
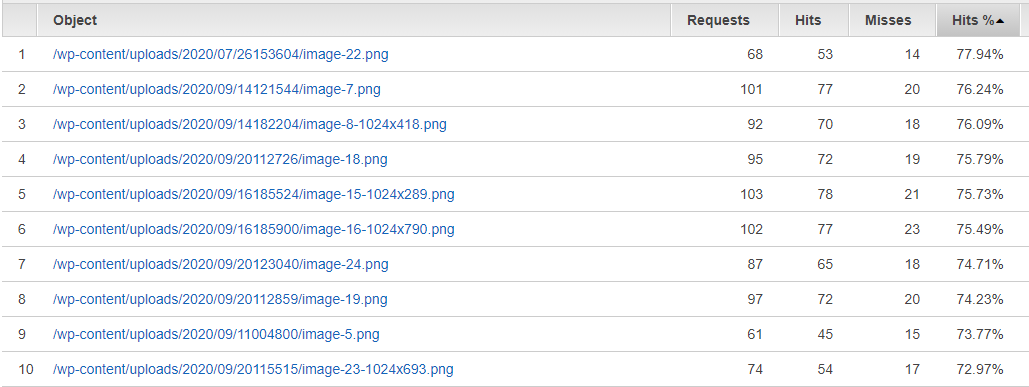
70%대다.
개판이다..이게 어떻게 변할까?
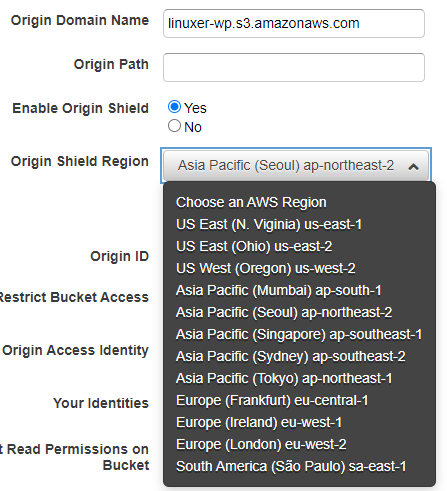
Origin Shield Region 으로 서울리전을 선택했다.
설정자체는 어려울게 하나도 없고 일단....
기다려 봐야겠다.
그리고 하루정도 지난상태로 포스팅 쓰는것을 이어간다.
먼저 어제의 히트율
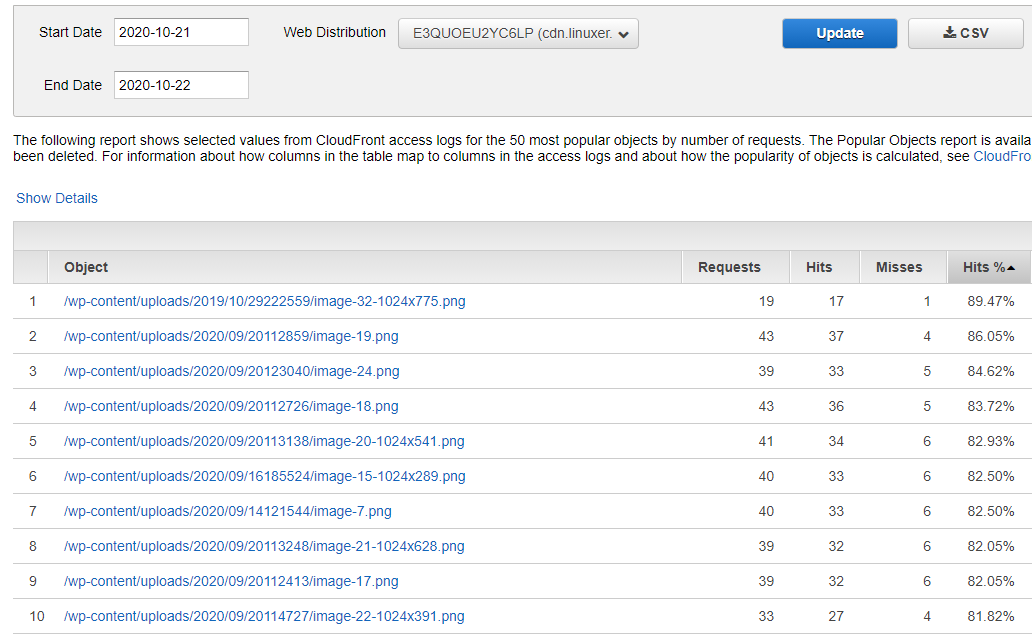
21 ~ 22일의 히트율.
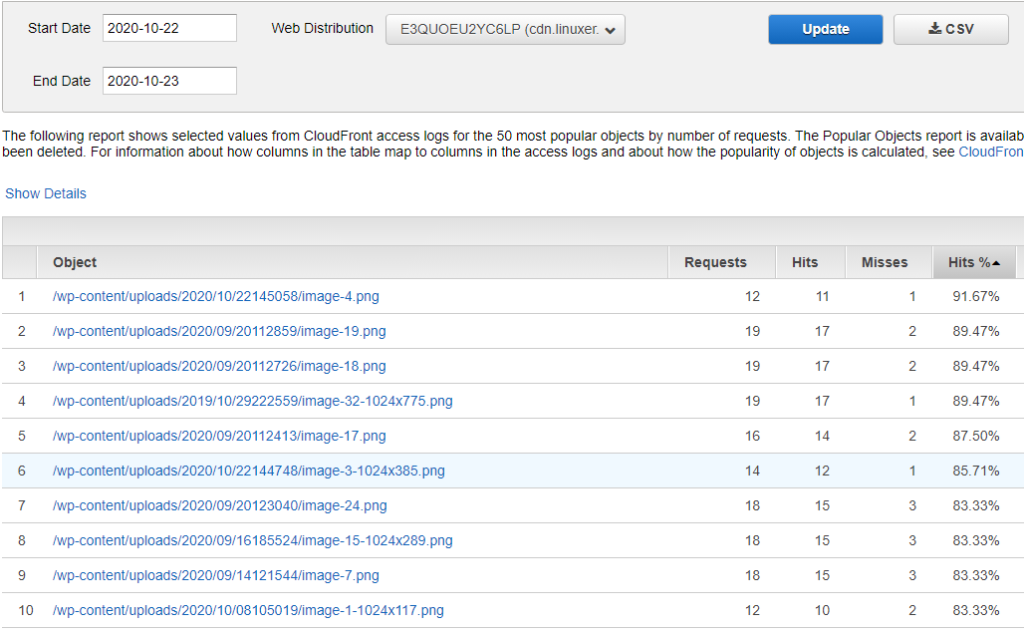
22 ~ 23일 오? 효과가 있다.
더 모니터링 이후 내용을 추가하겠다.
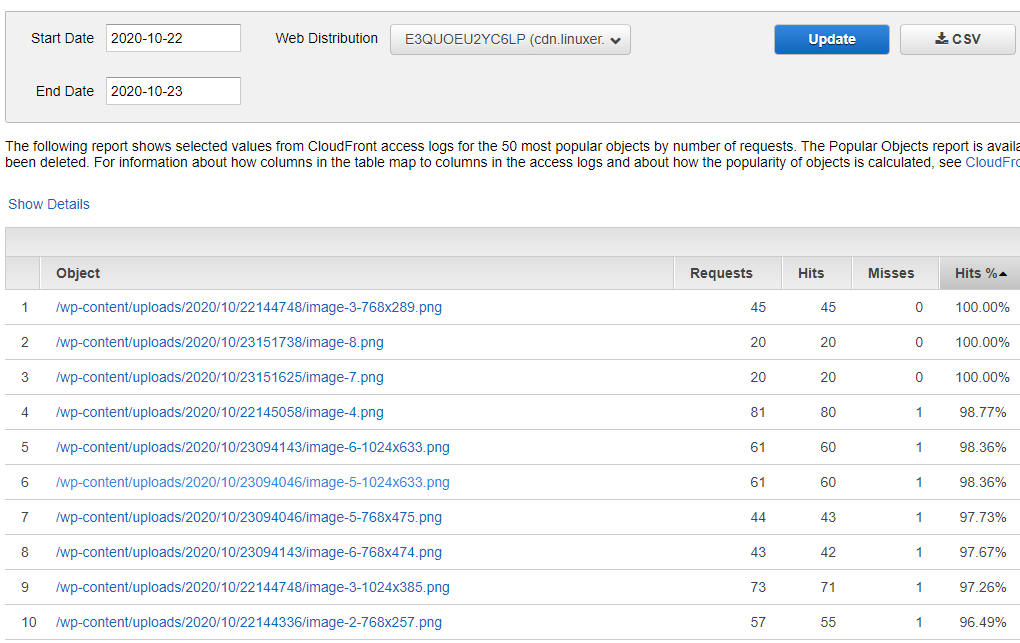
오후에 추가한 내용 오...히트율이 엄청올라간다. 만세! 유효한 효과가 있음을 확인하였다.