미뤘다가..못참고 내가한다.ㅠㅠ
먼저 인스턴스를 생성하고..

켜져있는 상태로 일단 수정해보자.
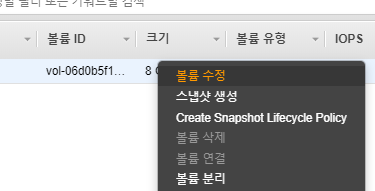
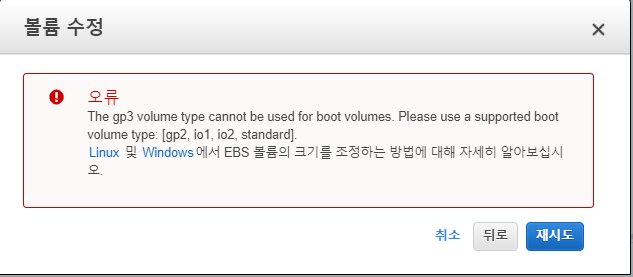
부트볼륨으론 지원하지 않는다...-_-;뭐양..
근데 DOCS 엔..
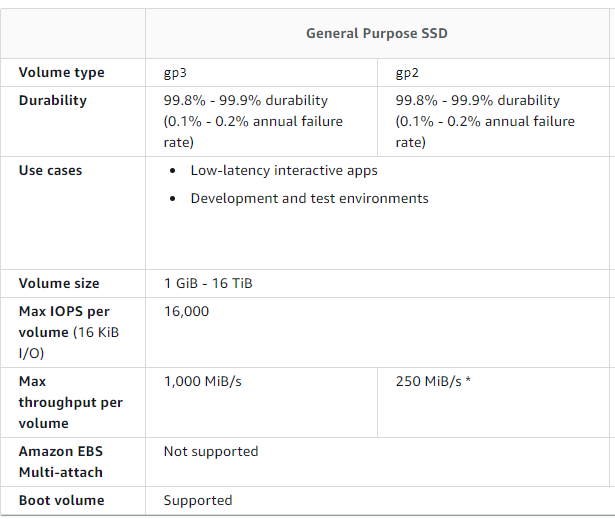
지원인데..아직미지원인가..?
이후 지원한다.
잘된다. 쓰세요!
미뤘다가..못참고 내가한다.ㅠㅠ
먼저 인스턴스를 생성하고..
켜져있는 상태로 일단 수정해보자.
부트볼륨으론 지원하지 않는다...-_-;뭐양..
근데 DOCS 엔..
지원인데..아직미지원인가..?
이후 지원한다.
잘된다. 쓰세요!

오오오오오오!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
macOS Catalina 10.15.7 버전을 쓸수있다.

뜨든... 인스턴스 유형은 베어 메탈뿐.. 그렇다고 해서 내가 안만들순없지 가즈아!!!!!
-_-;

전용 호스트가 필요하다....근데 전용 호스트 갯수는 not support 상태다 service quotas를 늘려야한다.
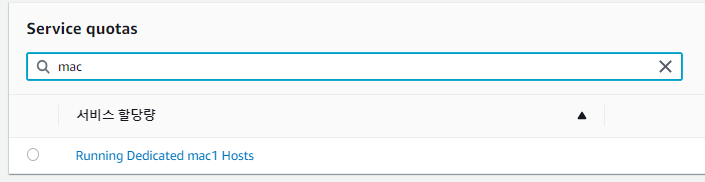
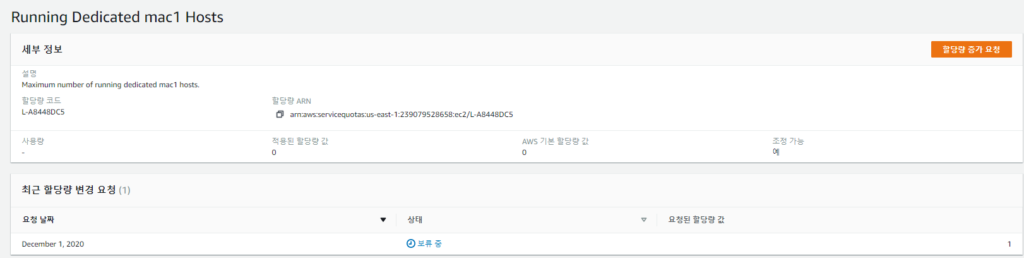
일단 바로 요청 근데 금방 안되나? 아마 지금 전세계에서 생성 중일거다..증가가 되면 바로 더 진행해 보겠다.

Maximum number of running dedicated mac1 hosts.
보류에서 할당량이 요청됨으로 변경됬다.
그리고 오늘 (12월2일) 요청은 허락되지 않고 기본 제공량이 3으로 변경됬다.

일단 전용호스트를 만들고, 인스턴스를 생성했다.

한방에 인스턴스가 전용호스트를 다 차지한다.
ssh -i linuxer.pem ec2-user@IP
.
ssh는 동일하게 ec2-user 계정으로 접근한다.
SSM을 이용한접근도 가능하다.

먼저 vnc 로 접근하는게 목적이므로brew로 vnc server 를 셋팅해야한다.
sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -configure -allowAccessFor -allUsers -privs -all sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -configure -clientopts -setvnclegacy -vnclegacy yes sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -configure -clientopts -setvncpw -vncpw supersecret sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -restart -agent -console sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -activate
https://gist.github.com/nateware/3915757
귀찮아서 이페이지 복붙했다. 위 명령어를 치면 vnc 가활성화 된다.
sudo dscl . -passwd /Users/ec2-user
.
명령어로 ec2-user의 패스워드를 설정한다.
그리고 VNC viewer 로 접속한다.
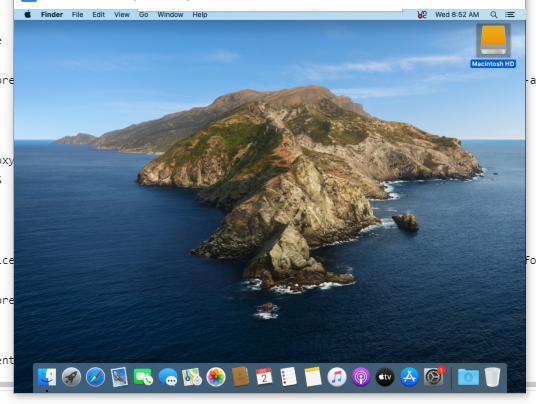
길고긴 여정을 지나 드디어.. 접속했다.
북미라 너무 느리다..-_-; VNC로 접속하기를 마무리한다.
관리형 RabbitMQ가 나왔다.

놀랄만큼 아무도 관심을 가지지 않았다. 안타깝....
그래서 내가 관심을 주기로 했다.
RabbitMQ VPC 설정을 확인해 보자!
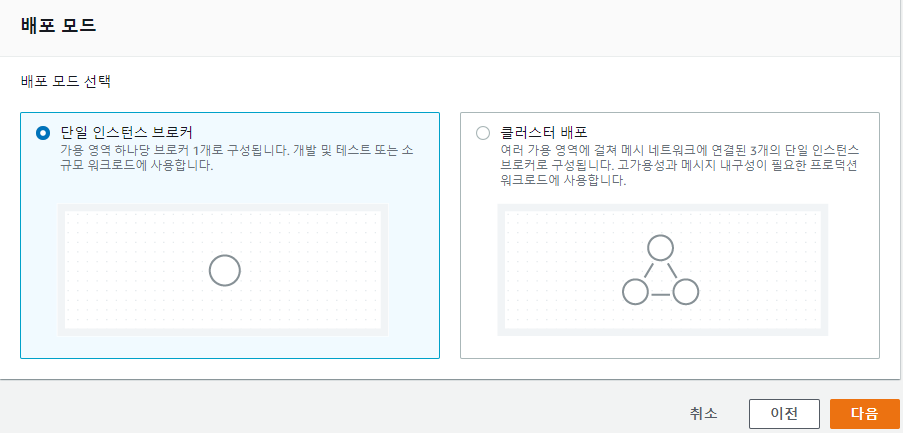
생성모드는 단일과 클러스터 두가지가 있다. 단일구성부터 보자
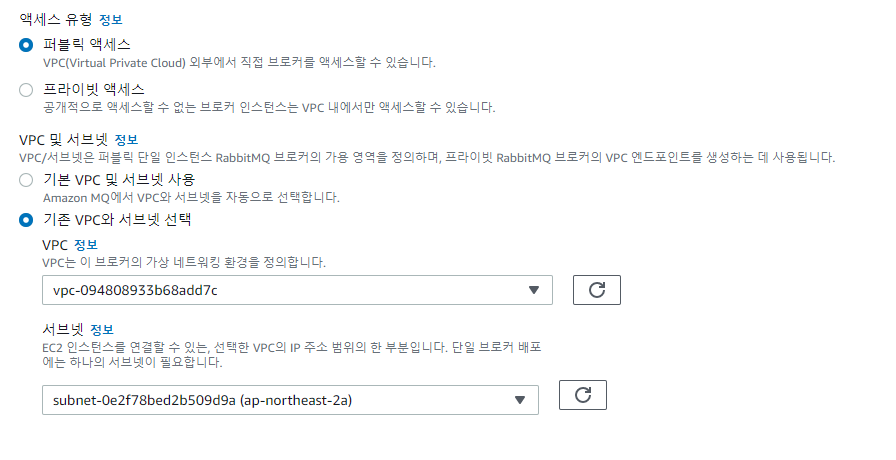
퍼블릭엑세스는 VPC 내에 속하며 서브넷을 선택할수 있다.
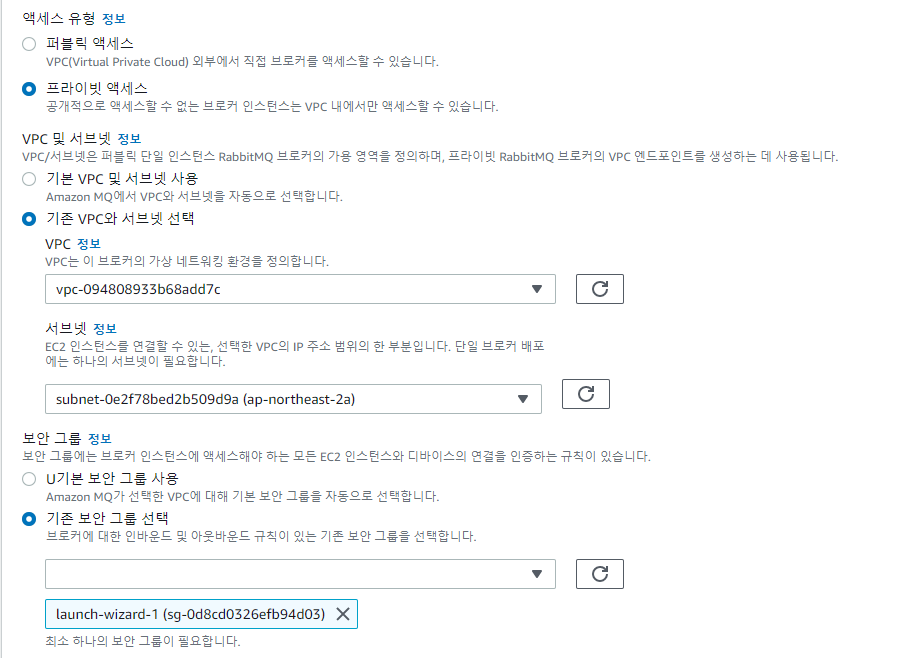
프라이빗 엑세스를 선택해야 보안그룹를 선택할수 있다. 이게 가장 큰 차이점.
그리고 한번 퍼블릭으로 생성한 MQ는 영원히 퍼블릭이다. 프라이빗은 영원히 프라이빗..
그리고 이 포스팅을 시작하게 된 가장 큰 계기..

클러스터 모드에서 퍼블릭 엑세스를 사용한 RabbitMQ 는 VPC 외부에 만들어진다.




그냥 VPC 컨트롤하는 설정이 없다.
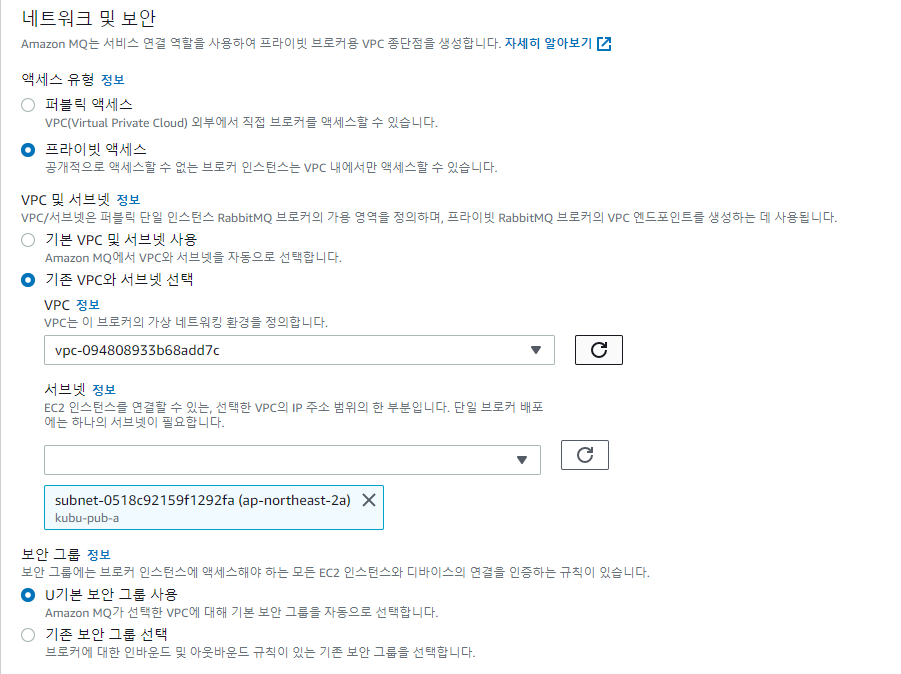
프라이빗으로 설정하면 VPC에 생성...
같은 RabbitMQ임에도 VPC 내부 / 외부 / 보안그룹 유 /무 접근제어 방식이 다른것이 인상적이었다. RDS와 같이 VPC 내부에 만들어져서 편리하게 전환할 수 있는 방식이 아니기에 생성 초기부터 명확하게 아키텍처를 구상해야 하는 것이다.
RabbitMQ의 VPC 설정은 변경이 불가능하다!!
읽어주셔서 감사합니다!
오늘 하시코프x네이버클라우드 웨비나에서 terraform 과 Vault 에 대한 웨비나를 청취했습니다.
https://github.com/NaverCloudPlatform/terraform-provider-ncloud
이전에 방과후(?) meetup에서 네이버클라우드가 테라폼의 프로바이더로 있다는것을 알았습니다. 그 덕분에 네이버클라우드에서 terraform은 이미 경험이 있는 상태고, Vault도 경험이 있었습니다. 오늘의 주제 중 Secrets Engines이 궁금했습니다.
https://www.vaultproject.io/docs/secrets
Secrets engines are components which store, generate, or encrypt data.
시크릿엔진은 데이터를 저장또는 생성하고 암호화하는 구성요소.
AWS 의 Parameter Store / Secrets Manager 와 비슷한 기능을 한다고 생각이 들었습니다. 다른 벤더에서도 비슷한 서비스들이 있습니다.
https://hackernoon.com/aws-secrets-manager-vs-hashicorp-vault-vs-aws-parameter-store-bcbf60b0c0d1
https://www.cloudjourney.io/articles/security/aws_secrets_manager_vs_hashi_vault-su/
가장 일반적인 사용예라 생각되는것은, access key의 암호화라 생각됩니다. 일반적으로 aws-vault 같은 명령어로 지원합니다.
아직 ncp-vault 가 만들어진게 아니라, ncp 내에서 사용하기엔 좀 불편한 부분이 있으리라 생각됩니다. 현재 npc 는 provider로 등록된 상태고 cli 를 지원하므로 차차 지원하리라 생각됩니다.
aws 에서의 vault 사용예입니다.
https://www.vaultproject.io/docs/secrets/databases/mysql-maria
mysql-maria db의 user 암호화입니다.
이런 방법이 필요한 이유는 결국 어플리케이션 소스의 탈취로 문제를 방지하기 위함입니다. key의 자동로테이션이나, expire time 을가진 key 발급등을 할 수 있습니다.
Vault 는 근래에 들어서 굉장히 핫한 오픈소스라 테스트 해보시는게 좋을것 같습니다.
마무리를 하자면..
템플릿 소스들이 점점 쌓이고 사용예가 늘면 IaC는 점점 더 일반화 될것입니다.
미리미리 IaC를 준비하고 사용방법을 익히는것도 좋을것 같습니다.
조만간 Secrets Engines 사용하기 위해 자동화 스크립트를 적용하는 고민을 한번 해보려 합니다. 시간이 나면 한번 테스트 해봐야겠습니다.
읽어주셔서 감사합니다!
https://www.cyberciti.biz/tips/linux-increase-outgoing-network-sockets-range.html
https://meetup.toast.com/posts/55
http://docs.likejazz.com/time-wait/
tcp port range는 32768에서 61000까지다 대략 28000개의 가용포트가 있다는것이다.
클라이언트로서 28000개의 가용포트를 모두사용하게되면?
더이상의 새로운 TCP 세션을 생성할수 없게된다.
#tcp port range echo 10240 60999 > /proc/sys/net/ipv4/ip_local_port_range
.
그래서 일단 10240 - 60999 개의 포트를 사용할수 있도록 수정해줬다.
예약포트들은 포통 10240 아래로 포진되어 있고, 61000 포트위로는 패시브 포트로 사용하는경우가 많으므로 일단 10240-61000포트를 사용할수 있도록 수정했다. 50000개 가량의 포트를 사용가능하도록 수정한거다.
그래도 해결이안되는듯 했다.
[root@linuxer ~]# netstat -an | grep TIME_WAIT | wc -l 51314
.
두배 이상의 port range 에도 처리가 불가능한 수준이었던것..
#tcp_timestamps 기본으로 이미 적용되어있음 $ sysctl -w ipv4.tcp_timestamps="1" #tcp reuse $ sysctl -w net.ipv4.tcp_tw_reuse="1"
.
그래서 두가지 방법중 tw_reuse / tw_recycle 둘중 하나를 사용하려했다. reuse 옵션은 소켓재활용, recycle 은 강제로 TIME_WAIT인 포트를 종료하는거다. 좀 더 시스템에 영향을 덜주는 방법인 reuse를 선택했다.
-홀스님의 첨언

.
tw_recycle은 서버입장에선 문제가 생길수있으니 설정에는 반드시 주의가 필요하다.
일단은 처리를 했고, 서비스의 동작을 모니터링중이다.
모든옵션을 켜는 방법이다. 참고하길..tcp_tw_recycle옵션은 사용할때 꼭 주의 해야한다
sysctl -w ipv4.tcp_timestamps="1" sysctl -w net.ipv4.tcp_tw_reuse="1" sysctl -w net.ipv4.tcp_fin_timeout="10"
.
일단 이 방법은 좀 임시방편이고, 좀 더 확장성있는 방법으로 가기위해선 scale out을 해야한다.
또 추가하자면..
FIN_WAIT2 / TIME_WAIT 두가지의 TCP 파라미터가 60초의 기본시간을 가지게 되어서 총 2분의 대기시간을 가지게 된다. 컨트롤 할수있는 파라미터는 FIN_WAIT2 상대의 파라미터를 수정 하는경우도 있다고 한다. 수정할수 있는파라미터는 대부분 /proc/sys/net/ipv4 경로에 위치하니 하나씩 확인해 보자.
글을 다쓰고 추가로 내용을 덕지덕지 붙인거라 깔끔하지 않다.
하지만 도움이 되길 바란다!
마지막으로 php-mysql은 커넥션풀이 없다고 알고있었는데 라이브러리가 있었다.
https://bkjeon1614.tistory.com/216
아직테스트는 해보지 않은 상태고, 슬슬 해보겠다.