https://www.cyberciti.biz/tips/linux-increase-outgoing-network-sockets-range.html
https://meetup.toast.com/posts/55
http://docs.likejazz.com/time-wait/
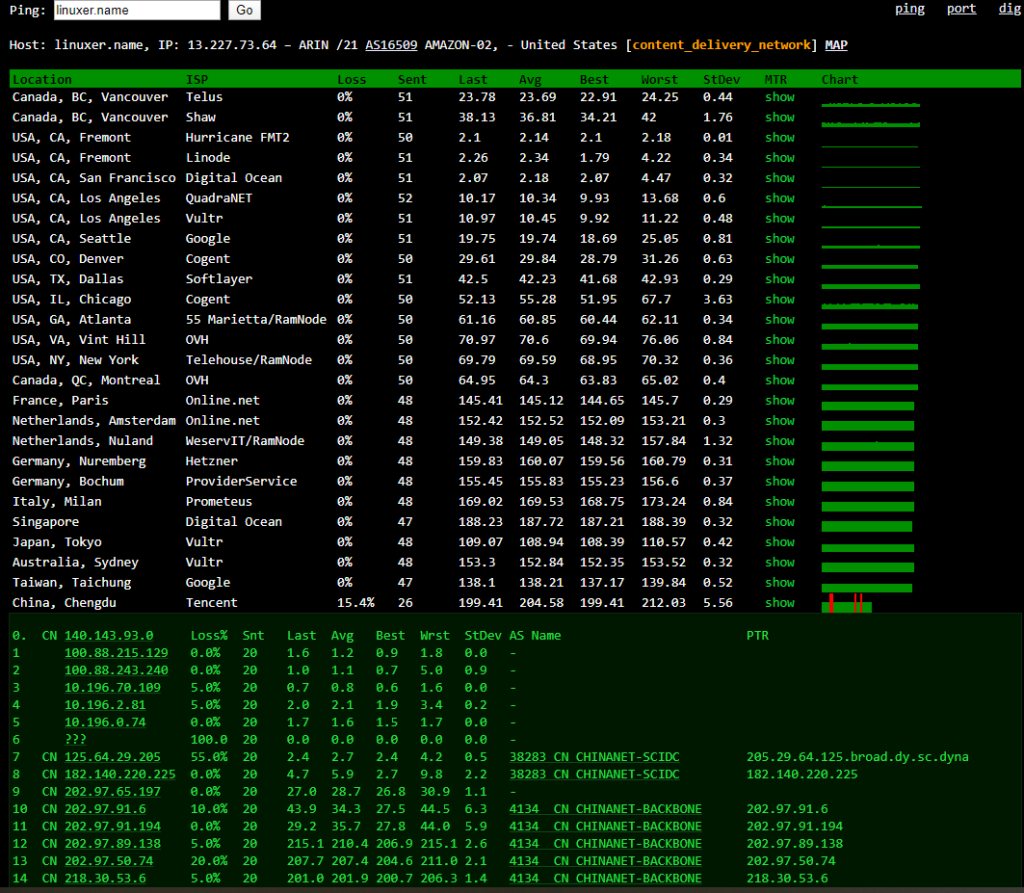
tcp port range는 32768에서 61000까지다 대략 28000개의 가용포트가 있다는것이다.
클라이언트로서 28000개의 가용포트를 모두사용하게되면?
더이상의 새로운 TCP 세션을 생성할수 없게된다.
#tcp port range echo 10240 60999 > /proc/sys/net/ipv4/ip_local_port_range
.
그래서 일단 10240 - 60999 개의 포트를 사용할수 있도록 수정해줬다.
예약포트들은 포통 10240 아래로 포진되어 있고, 61000 포트위로는 패시브 포트로 사용하는경우가 많으므로 일단 10240-61000포트를 사용할수 있도록 수정했다. 50000개 가량의 포트를 사용가능하도록 수정한거다.
그래도 해결이안되는듯 했다.
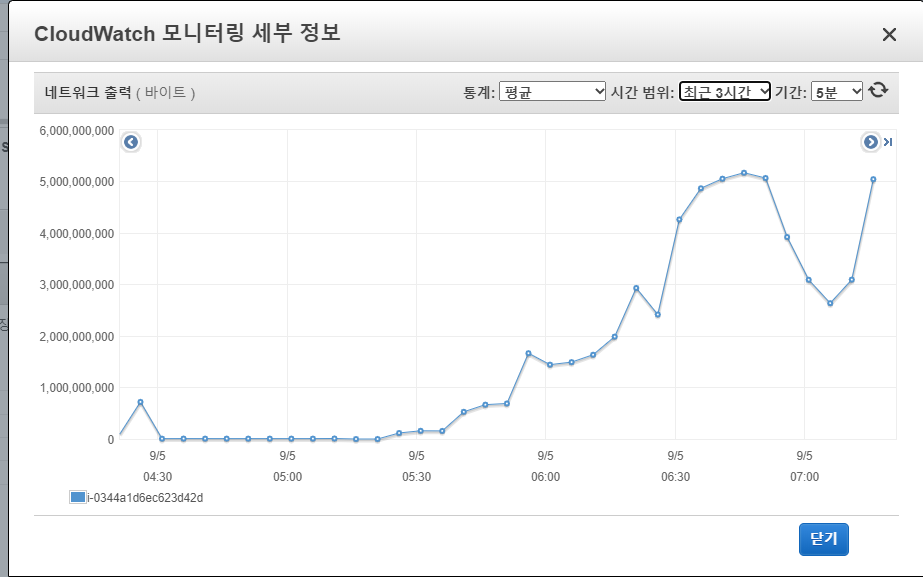
[root@linuxer ~]# netstat -an | grep TIME_WAIT | wc -l 51314
.
두배 이상의 port range 에도 처리가 불가능한 수준이었던것..
#tcp_timestamps 기본으로 이미 적용되어있음 $ sysctl -w ipv4.tcp_timestamps="1" #tcp reuse $ sysctl -w net.ipv4.tcp_tw_reuse="1"
.
그래서 두가지 방법중 tw_reuse / tw_recycle 둘중 하나를 사용하려했다. reuse 옵션은 소켓재활용, recycle 은 강제로 TIME_WAIT인 포트를 종료하는거다. 좀 더 시스템에 영향을 덜주는 방법인 reuse를 선택했다.
-홀스님의 첨언

.
tw_recycle은 서버입장에선 문제가 생길수있으니 설정에는 반드시 주의가 필요하다.
일단은 처리를 했고, 서비스의 동작을 모니터링중이다.
모든옵션을 켜는 방법이다. 참고하길..tcp_tw_recycle옵션은 사용할때 꼭 주의 해야한다
sysctl -w ipv4.tcp_timestamps="1" sysctl -w net.ipv4.tcp_tw_reuse="1" sysctl -w net.ipv4.tcp_fin_timeout="10"
.
일단 이 방법은 좀 임시방편이고, 좀 더 확장성있는 방법으로 가기위해선 scale out을 해야한다.
또 추가하자면..
FIN_WAIT2 / TIME_WAIT 두가지의 TCP 파라미터가 60초의 기본시간을 가지게 되어서 총 2분의 대기시간을 가지게 된다. 컨트롤 할수있는 파라미터는 FIN_WAIT2 상대의 파라미터를 수정 하는경우도 있다고 한다. 수정할수 있는파라미터는 대부분 /proc/sys/net/ipv4 경로에 위치하니 하나씩 확인해 보자.
글을 다쓰고 추가로 내용을 덕지덕지 붙인거라 깔끔하지 않다.
하지만 도움이 되길 바란다!
마지막으로 php-mysql은 커넥션풀이 없다고 알고있었는데 라이브러리가 있었다.
https://bkjeon1614.tistory.com/216
아직테스트는 해보지 않은 상태고, 슬슬 해보겠다.

{kind=link}