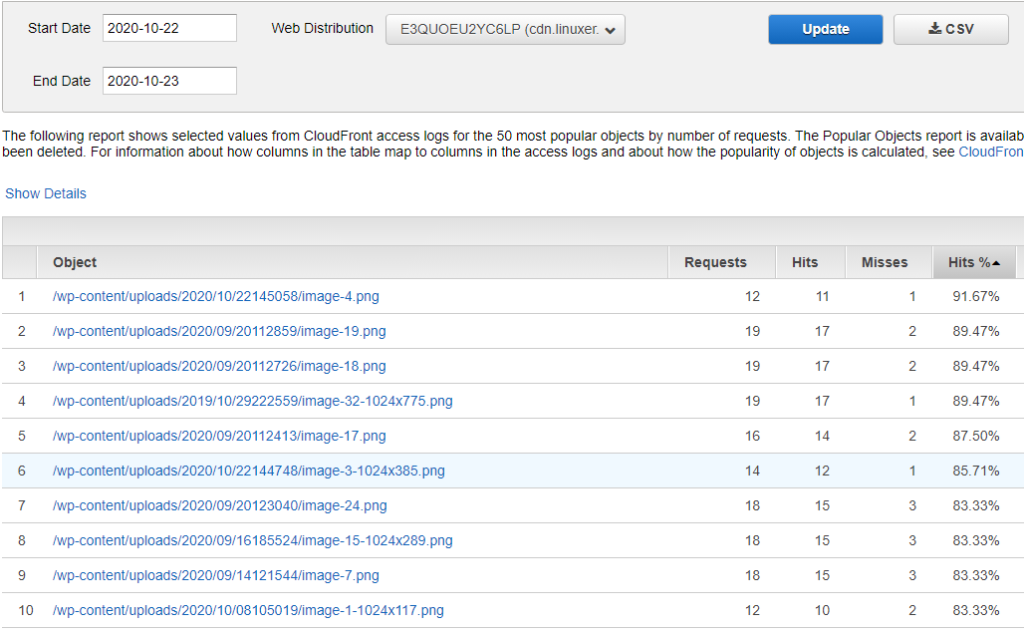
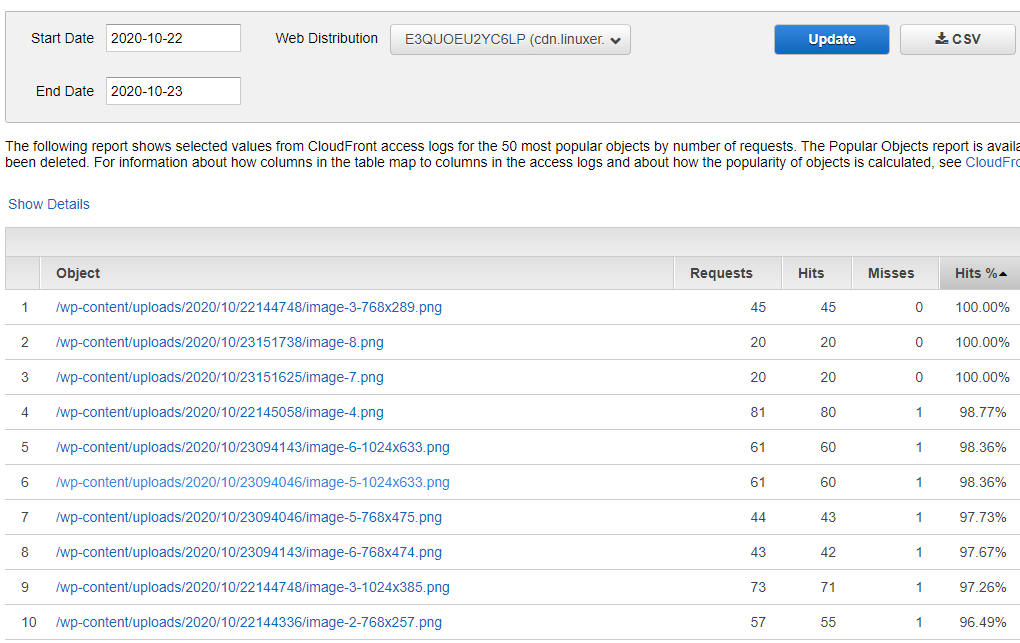
#!/bin/sh setenforce 0 sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux swapoff -a modprobe br_netfilter echo '1' > /proc/sys/net/bridge/bridge-nf-call-iptables yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo yum install -y docker-ce cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOF yum install -y kubelet kubeadm kubectl systemctl enable docker systemctl enable kubelet sed -i 's/cgroup-driver=systemd/cgroup-driver=cgroupfs/g' /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
K8s centos7 base install
userdate 등에 넣고 쓸수있다.
#Master 에서 작업
kubeadm init --pod-network-cidr=사용하려는 pod cidr
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeadm join token 이 나오면 cluster node 에서 join 해준다