이번주 스터디는 K8S에서의 Pometheus Grafana 다.
이글은 chatgpt를 이용해서 삽질하는 리눅서를 담고있다.
프로메테우스는 아이콘이 불꽃 모양인데 정말 모니터링계에 불을 가져다준 혁신과도 같은 존재다. 이전에는 Nagios / Zabbix가 나눠먹고 있었다.
나는 이번에 뭘 모니터링 해볼까 고민하다가 HPA를 모니터링 해볼까한다.
먼저 내가 요즘 일하는 방식을 보여줄까한다.

바로 Chatgpt다.

apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer

apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
go 기반이라 bash로 수정해달라고 했다.
#!/bin/bash
SERVICE_IP=$(kubectl get svc nginx-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
CONCURRENCY=100
REQUESTS=50000
# Run load test
for i in $(seq 1 $CONCURRENCY); do
(for j in $(seq 1 $(($REQUESTS / $CONCURRENCY))); do
curl -s -o /dev/null http://${SERVICE_IP}/
done) &
done
# Wait for all background processes to complete
wait
위의 Manifast 를 적용한 결과는 다음과 같다.
k get all NAME READY STATUS RESTARTS AGE pod/nginx-deployment-7c6895c677-cblrh 1/1 Running 0 15s pod/nginx-deployment-7c6895c677-s6b5c 1/1 Running 0 15s pod/nginx-deployment-7c6895c677-smkxv 1/1 Running 0 15s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/nginx-service LoadBalancer 100.66.65.216 <pending> 80:30979/TCP 15s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx-deployment 3/3 3 3 15s NAME DESIRED CURRENT READY AGE replicaset.apps/nginx-deployment-7c6895c677 3 3 3 15s NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE horizontalpodautoscaler.autoscaling/nginx-hpa Deployment/nginx-deployment <unknown>/50% 3 10 3 19s
정말 잘동작한다.
이제 ingress 답변을 받았다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-service
port:
number: 80
k get ingress NAME CLASS HOSTS ADDRESS PORTS AGE my-ingress <none> * k8s-nginx-myingres-106681c1f1-1873214288.ap-northeast-2.elb.amazonaws.com 80 72s
ingress - svc - deployment - hpa 구조 같은건 이제 3분이면 나온다.
gpt가 알려준 스크립트중
kubectl get svc nginx-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
부분을
kubectl get ingress my-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'
다음과 같이 수정하였다.
curl k8s-nginx-myingres-106681c1f1-1873214288.ap-northeast-2.elb.amazonaws.com
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
잘 뜬다.
이제 공격 간다
굉장한 스크립트 였다... 한방에 100개의 스크립트가 떴다...후....
근데 nginx 는 너무 가벼운 친구라...ㅠㅠ hpa 가 잘작동하지 않았다. 리미트를 준다.
resources:
limits:
cpu: 15m
memory: 10Mi
requests:
cpu: 15m
memory: 10Mi
k get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/nginx-deployment 33%/50% 3 10 3 25m
좋다 적절하다.
이제 셋업은 다되었다. hpa 가 동작하는 대시보드와 hap 가 일정이상 동작해서 max 에 가 까워지면 알럿을 날릴거다.
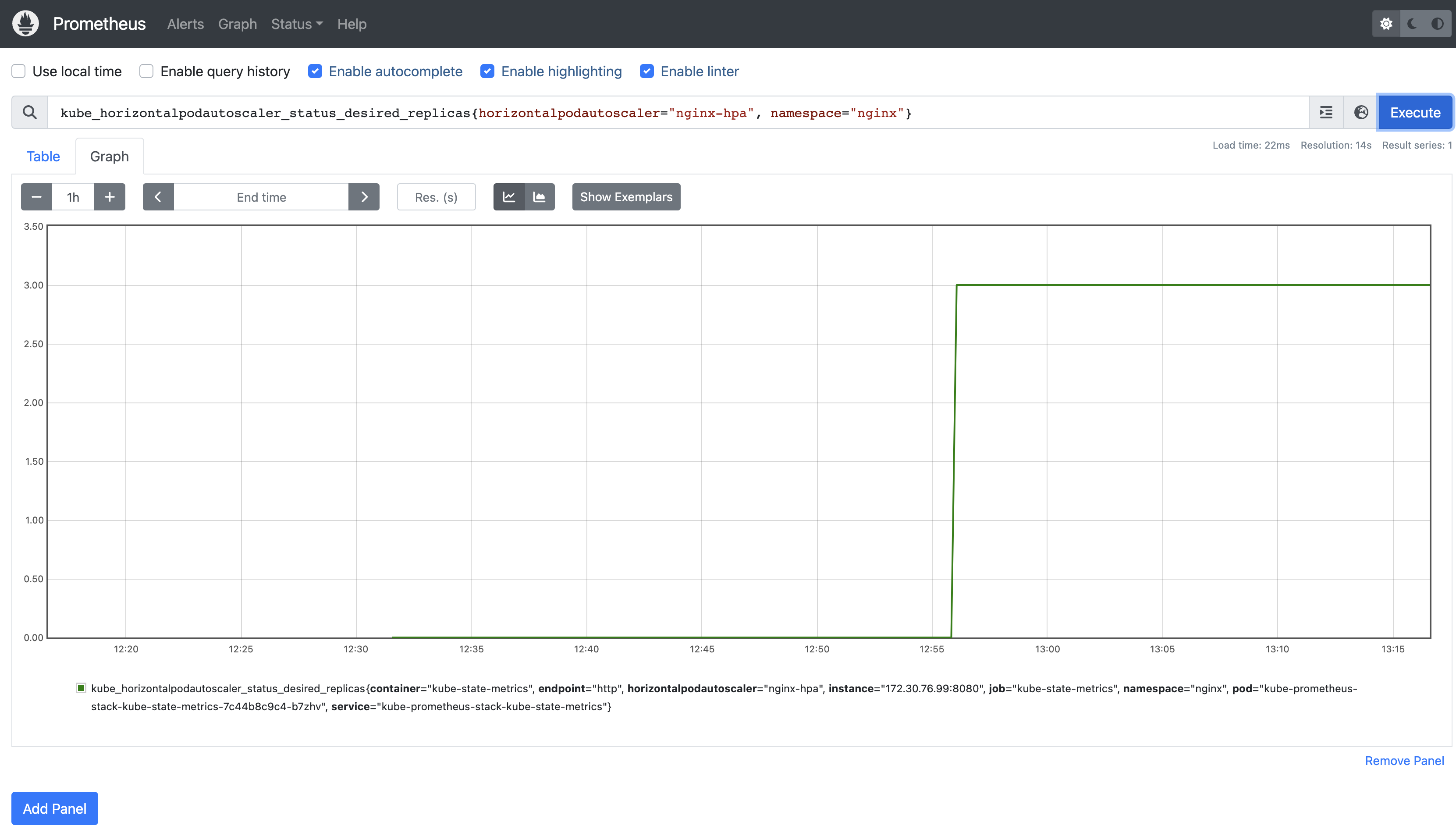
Chatgpt에게 물었고, 비슷한 쿼리를 작성했다.
kube_horizontalpodautoscaler_status_desired_replicas{horizontalpodautoscaler="nginx-hpa", namespace="nginx"}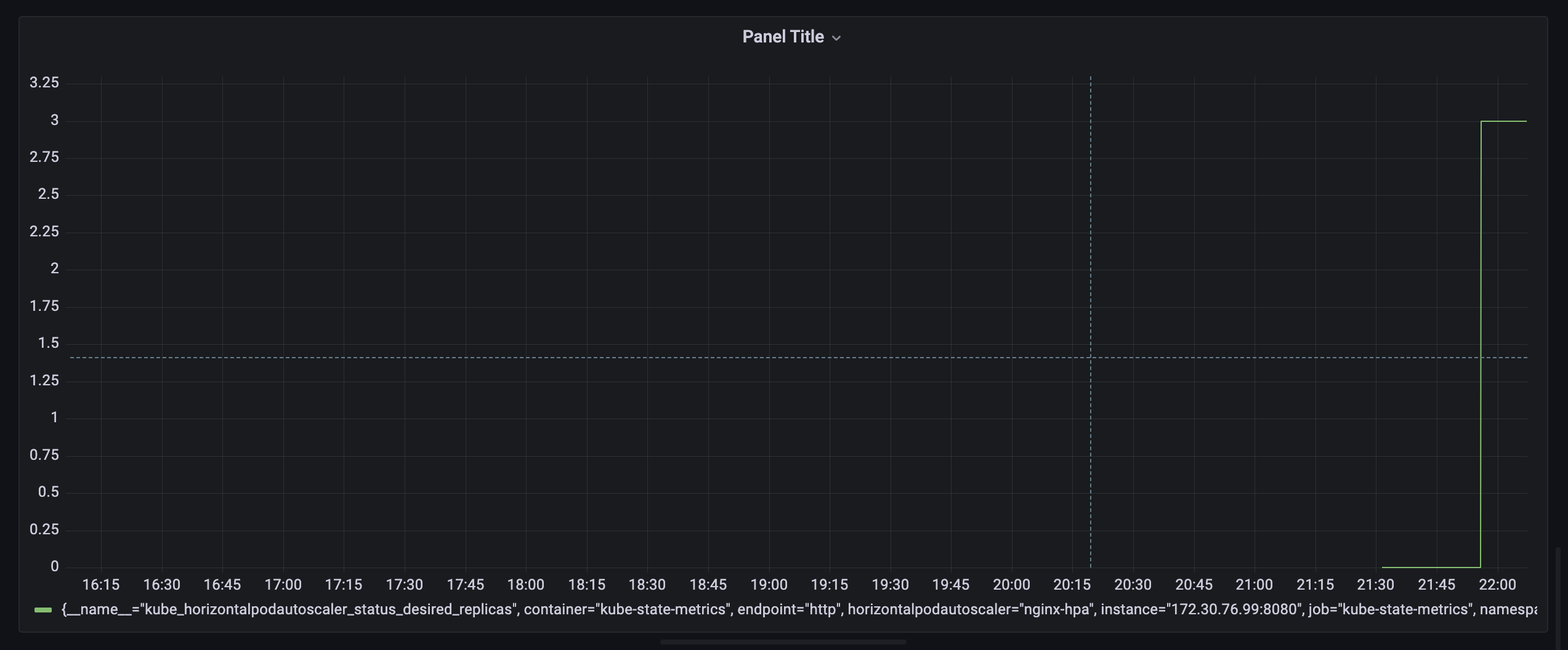
결과는 잘 작동한다. 그럼이걸 알럿을 보낼거다.
프로메테우스에서 graph로 grafana 에서 가져온 쿼리를 넣는다
1- avg(rate(kube_horizontalpodautoscaler_status_desired_replicas{horizontalpodautoscaler="nginx-hpa", namespace="nginx"}[1m]))
k edit cm prometheus-kube-prometheus-stack-prometheus-rulefiles-0 configmap/prometheus-kube-prometheus-stack-prometheus-rulefiles-0 edited

edit 로 수정했다.
추가를 하다가 잘 안되서 helm에 있는 config를 뜯어봤다. 어떤구성인지,
containers:
- env:
- name: BITNAMI_DEBUG
value: "false"
- name: NGINX_HTTP_PORT_NUMBER
value: "8080"
image: docker.io/bitnami/nginx:1.23.3-debian-11-r17
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 6
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: http
timeoutSeconds: 5
name: nginx
ports:
- containerPort: 8080
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
tcpSocket:
port: http
timeoutSeconds: 3
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
- command:
- /usr/bin/exporter
- -nginx.scrape-uri
- http://127.0.0.1:8080/status
image: docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: metrics
scheme: HTTP
initialDelaySeconds: 15
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
name: metrics
ports:
- containerPort: 9113
name: metrics
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: metrics
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
shareProcessNamespace: false
terminationGracePeriodSeconds: 30
exporter 가 사이드카로 붙어서 모니터링을 하고있었다.
https://github.com/nginxinc/nginx-prometheus-exporter
온종일 삽질의 연속이다가 오늘또 k8s에서의 프로메테우스와 그라파나 패턴을 까보면서 helm을 써야할까 하는 고민이들었다. kustomize를 고민했는데 좀더 뭘깍을지 생각해봐야겠다.
