로드벨런서의 사용용도는 뭘까?
말그대로 부하분산을 위한 장치이다.
부하분산을 위해선 기본적으로 헬스체크가 되어야 하고 헬스체크 간격과 인터벌이 중요하다.
예를들어 인터벌30초에 헬스체크2회 라고하면 Failover 의 기대 시간은 59초인것이다.
시작 점 0초 에서 헬스체크를 성공후에 1초부터 어플리케이션이 문제가 생기게 되면 총59초의 간격동안 마지막 헬스체크가 실패하여야 Failover가 발생한다.
이론상으로 그런데.......이게 좀 이상했다.
기대시간에 NLB가 전혀 미치지 못했다. 나열해 보자면..
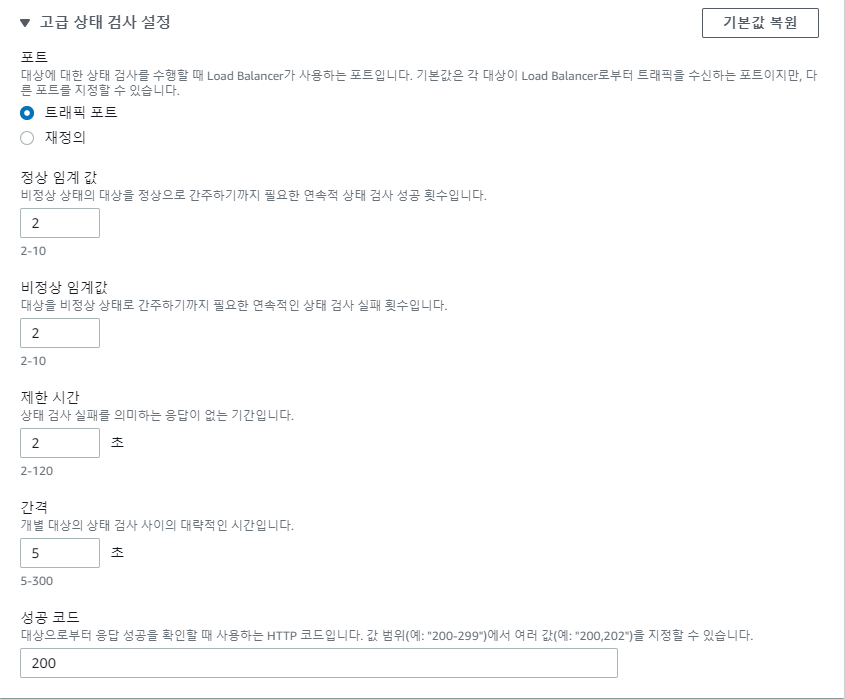
ALB의 최소 상태검사 시간이다. 인터벌5초 임계값2 총 9초안에 인스턴스의 unhealthy를 감지하고 트래픽의 라우팅을 멈춘다. ALB는 기대스펙과 동일하게 작동했다.
proxy 방식이라 당연히 그러하리라 생각했다. 문제가 생긴것은 NLB 였다.
NLB는 헬스체크 방식이 여러가지다. NLB의 대상그룹을 만들기 위해선 HTTP/HTTPS 가 아닌 프로토콜로 대상그룹을 생성하면 된다. 예를 들기 위해서 TCP를 사용했다.
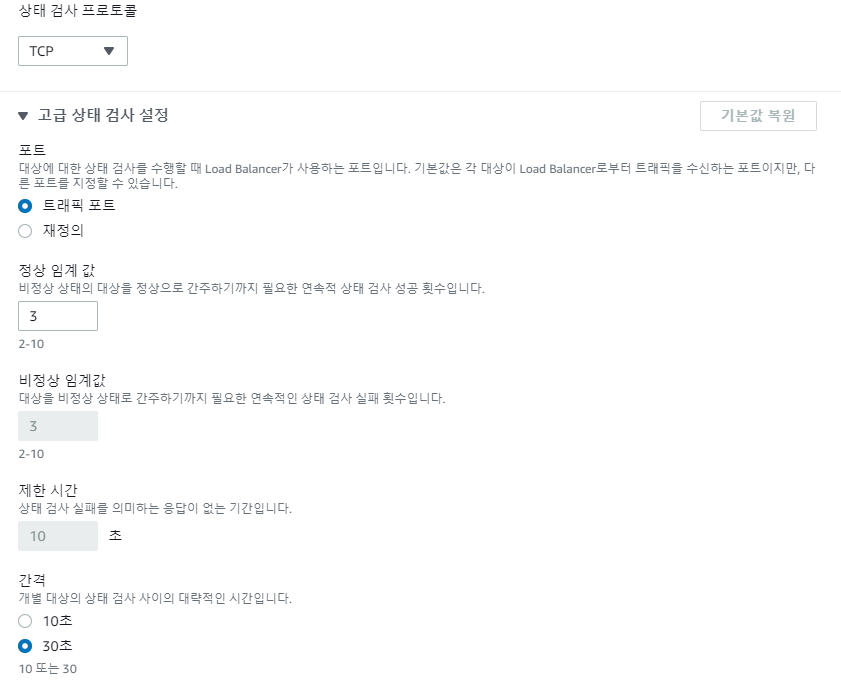
상태 검사 프로토콜이 TCP 일 경우 인터벌 30초 임계값2가 최소 스펙이다. ALB에 비해 엄청나게 느린것이다. 이것을 짧게 수정하고 싶다면 상태검사 프로토콜을 HTTP로 해야한다. 대상그룹의 대상 프로토콜은 TCP로 하되 상태검사는 HTTP로 하는것이다. 대상과 상태검사의 프로토콜을 별도로 사용할수 있는것이다.
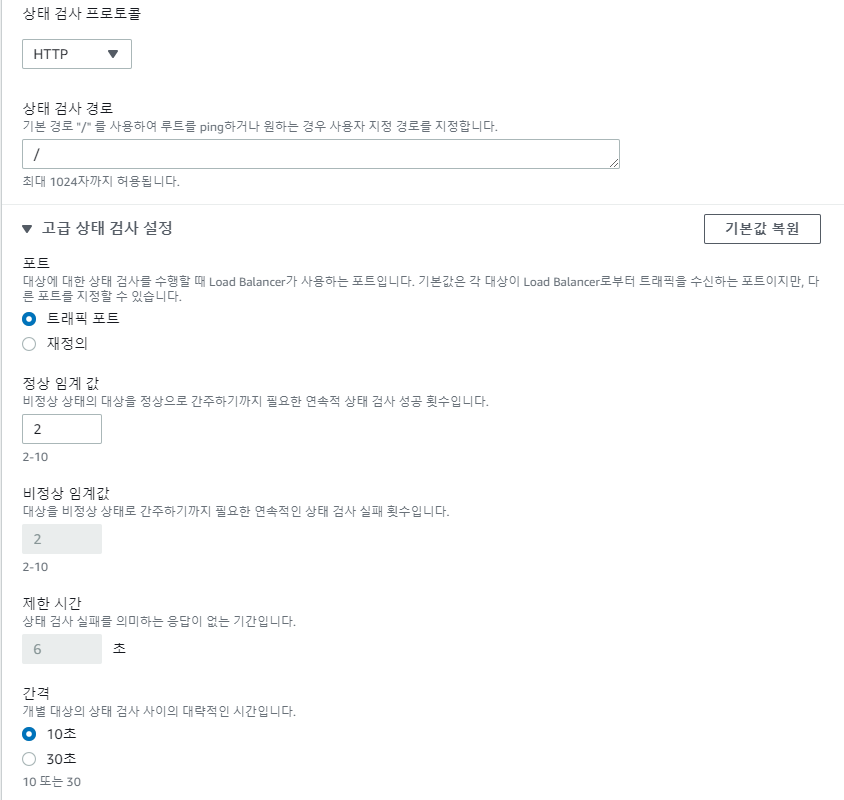
이제 10초의 인터벌 2회의 임계값을 가지게 되므로 19초에 페일오버가 되어야 한다.
그런데 이게 잘 안됬다.
!/bin/sh
date +"%y%m%d%H" >> $(date +"%y%m%d%H").txt
while true
do
STATUS=$(curl -# -o /dev/null -I -w %{http_code} -s -XGET http://test11-26d09f1385549f3c.elb.ap-northeast-2.amazonaws.com)
if [ $STATUS -eq 200 ]; then
echo 성공 >> $(date +"%y%m%d%H").txt
else
count=$(($count+1))
echo 실패 >> $(date +"%y%m%d%H").txt
fi
count=$(($count+1))
echo $count >> $(date +"%y%m%d%H").txt
sleep 1
done위 스크립트로 1초마다 사이트를 호출해서 상태코드가 200이면 성공 그외엔 실패를 찍게된다. 그리고 1번 돌때마다 카운트를 1씩 더 한다.
1차 테스트 - 71초
6 실패 . . 77 실패
2차 테스트 - 53초
6 실패 . . 59 실패
이후 테스트들은 대부분 비슷한 시간 50~79초 사이에 페일오버 되었다.
전환시간은 최대 79초 까지 걸렸다. 여기서 NLB의 TTL을 확인해 봤다.
[root@linuxer home]# nslookup -type=cname -debug http://test11-26d09f1385549f3c.elb.ap-northeast-2.amazonaws.com
Server: 10.0.0.2
Address: 10.0.0.2#53
------------
QUESTIONS:
http://test11-26d09f1385549f3c.elb.ap-northeast-2.amazonaws.com, type = CNAME, class = IN
ANSWERS:
AUTHORITY RECORDS:
-> elb.ap-northeast-2.amazonaws.com
origin = ns-679.awsdns-20.net
mail addr = awsdns-hostmaster.amazon.com
serial = 1
refresh = 7200
retry = 900
expire = 1209600
minimum = 60
ttl = 33
ADDITIONAL RECORDS:
------------nslookup -type=cname -debug http://test11-26d09f1385549f3c.elb.ap-northeast-2.amazonaws.com
명령어로 확인시에 TTL 이 minimum = 60으로 페일오버될때 까지 ttl 이 모두 소모될때까지 기다려야 페일 오버가 가능하다. 조금 이해가 안가는 부분이 있는데..이부분은 AWS 내부로직이라 추측을 했다.
Network Load Balancer relies on Domain Name System (DNS) to distribute requests from clients to the Load Balancer nodes deployed in multiple Availability Zones.
이내용을보면 DNS round robin 방식으로 여러개의 노드에 연결해주고 노드에선 다시 인스턴스에 연결해준다. 노드는 헬스체크에 따라 라우팅 하게되는데 노드의 TTL은 알수없으니 어느곳의 TTL로 인하여 페일오버의 지연이 발생하는지 알수없으나,
내가 원한 시간에 NLB는페일오버를 할수 없었다.
3rd party 의 LB 등 고민을 해봤으나 비용과 현실적인 문제로 페일오버의 기준을 맞추기 어려웠다. 그러던중 CLB 로 눈길이 갔다.
CLB는 http ~ tcp 까지 지원하는 이전 형식의 로드벨런서다.

CLB는 TCP 지원에 인터벌5초 임계값2로 9초로 페일오버가 되어야한다.
테스트 결과를 남기지 않아 아쉽지만 CLB는 기대치대로 동작하였다.
이 테스트 과정에서 얻은것이 몇가지 있다.
- 우리는 ELB의 성능을 모두 알 수 없다. 어디서도 ELB의 max limite 를 공식적으로 발표한 자료가 없다.
- NLB 와 CLB의 성능적인 차이는 있다.
- 최저 헬스체크 타임은 ALB9초=CLB9초>NLB19초 순이다.
결론: CLB또한 쓸데가 있었다.
